Hi all,
In this post, we would like to proudly introduce our upcoming feature: Aggregate Awareness.
Background
Imagine you have a fact table called orders that contains data of every order made on your e-commerce platform. Throughout your 5 years in business, the table orders has accumulated billions of rows.
Now, in order to answer questions like “Total number of items ordered in each year”, the database has to crunch through those billions of rows and aggregate the total. This process may take several minutes to complete and consume lots of database resources (typically memory and CPU)!
On the other hand, towards business users, this is a very simple question. In their eyes, they just need 5 numbers, 1 for each year. “Why does it take so long to get 5 numbers?!”
In data engineering and analytics, “pre-aggregation” is a well-known tool/technique to serve data questions like this faster.
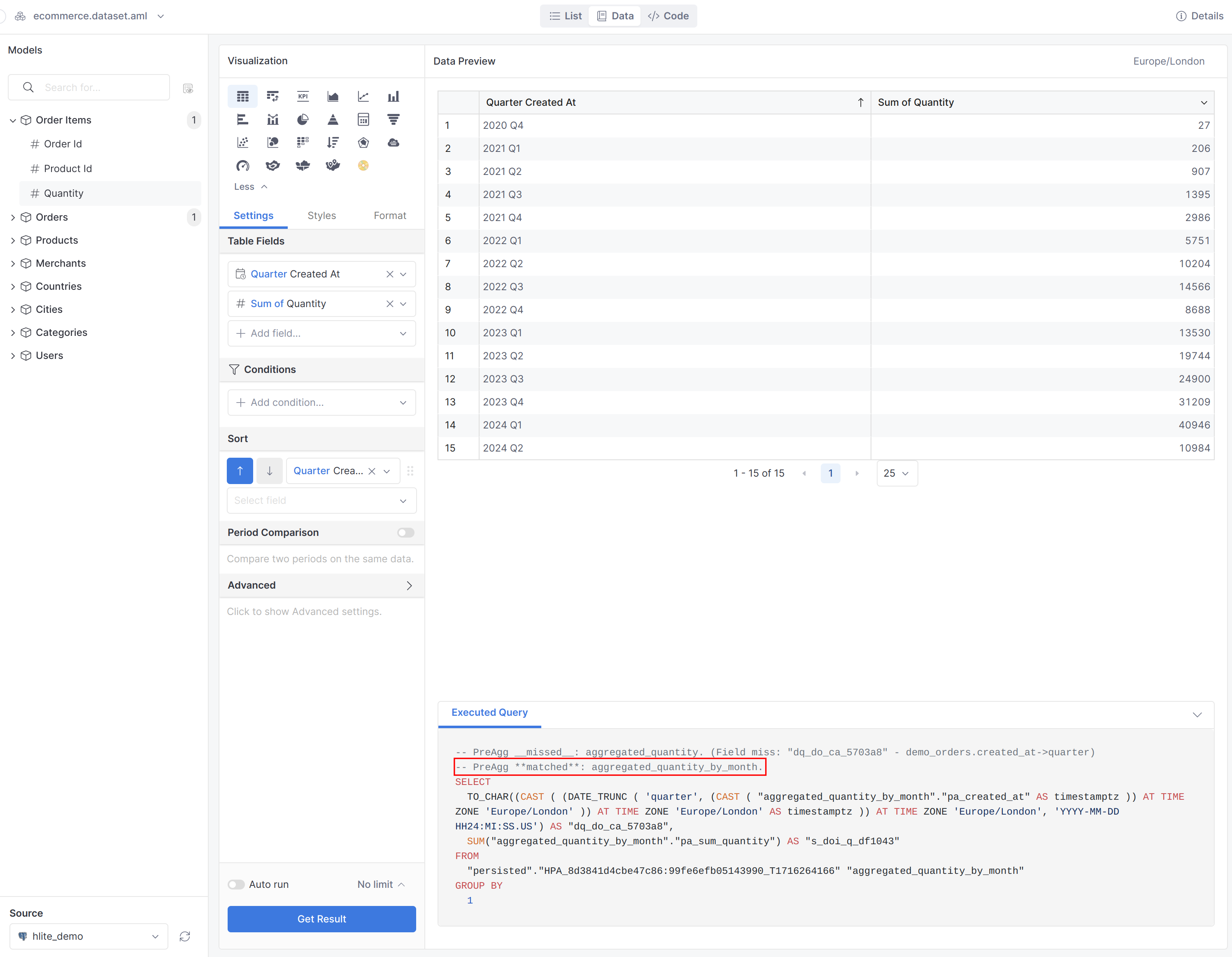
Essentially, the data engineer can “pre-aggregate” the orders table into total_quantity_by_month or total_quantity_by_year. Such “pre-aggregation” is done ahead of the business users’ usage, so that when the business users actually ask the question, the system can just process total_quantity_by_month (~ 60 rows) or total_quantity_by_year (~5 rows) and pull out the answer immediately!
Challenges
In the context of self-serve analytics where the business users use the Business Intelligence platform themselves to “query” or “explore” the data, it is actually quite challenging to make sure those users are correctly using the pre-aggregated tables like total_quantity_by_month or total_quantity_by_year instead of orders. This raises the need for the BI platform to be “aggregation-aware” and be able to automatically use the appropriate pre-aggregates for the business users.
Additionally, it requires significant effort and skills for the data engineers to maintain the pre-aggregates, keeping them accurate and up-to-date.
Aggregate Awareness 
To solve the above challenges, Holistics is developing Aggregate Awareness that consists of these sets of features:
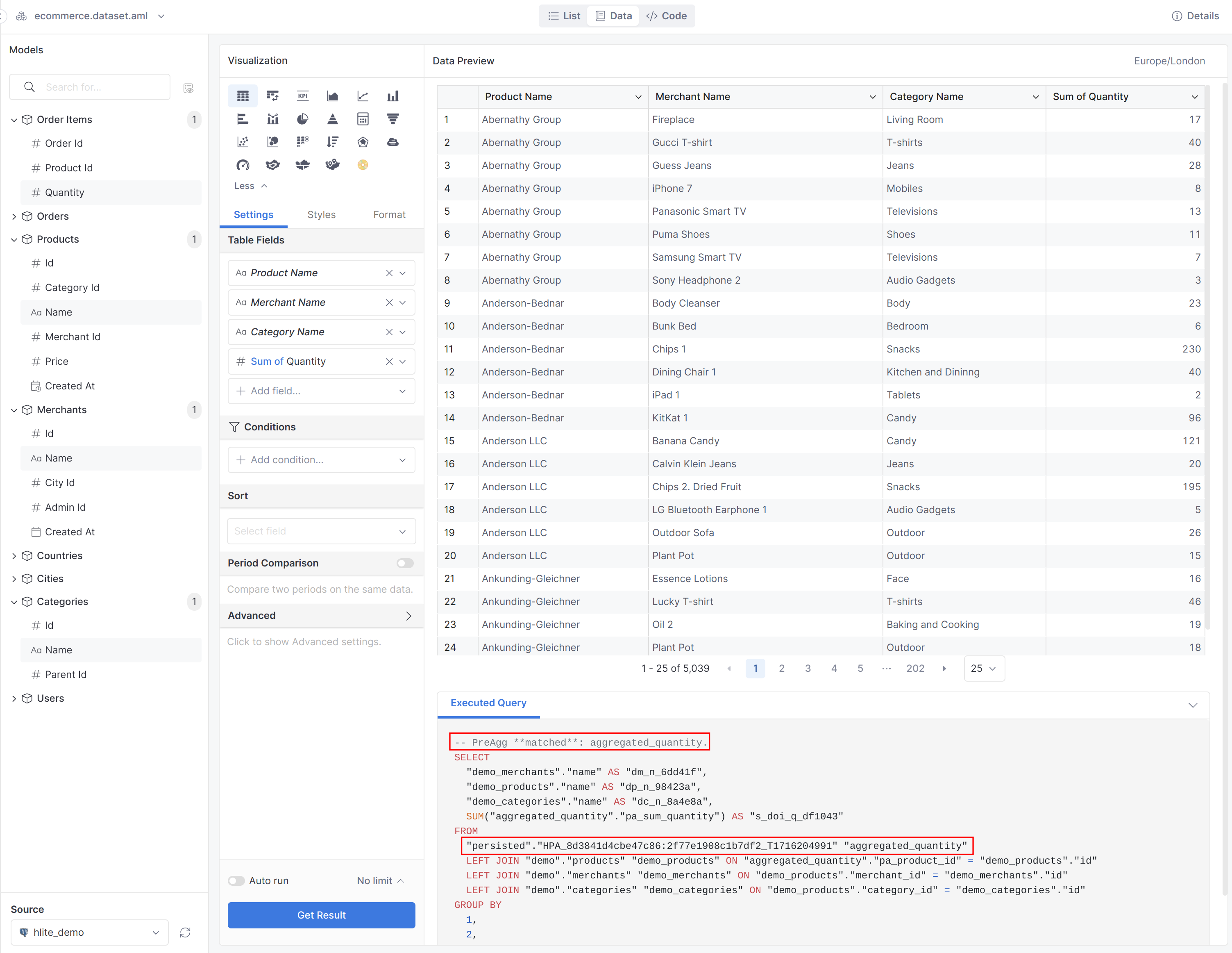
 Aggregate Awareness: automatically identify eligible pre-aggregates and substitute them into queries, making the queries use smaller pre-aggregated tables while still producing accurate results.
Aggregate Awareness: automatically identify eligible pre-aggregates and substitute them into queries, making the queries use smaller pre-aggregated tables while still producing accurate results. Pre-Aggregate Definition: allow analytic engineers to conveniently define the pre-aggregates
Pre-Aggregate Definition: allow analytic engineers to conveniently define the pre-aggregates Pre-Aggregate Persistence: allow analytic engineers to conveniently and accurately persist/materialize the pre-aggregates
Pre-Aggregate Persistence: allow analytic engineers to conveniently and accurately persist/materialize the pre-aggregates Pre-Aggregate Suggestions (later): automatically suggest relevant pre-aggregates to speed up your explorations and reports.
Pre-Aggregate Suggestions (later): automatically suggest relevant pre-aggregates to speed up your explorations and reports.
Please take a first look at the usage of Aggregate Awareness via this tutorial: Using Aggregate Awareness | Holistics Docs (4.0).
Here are some snippets taken from the above tutorial:
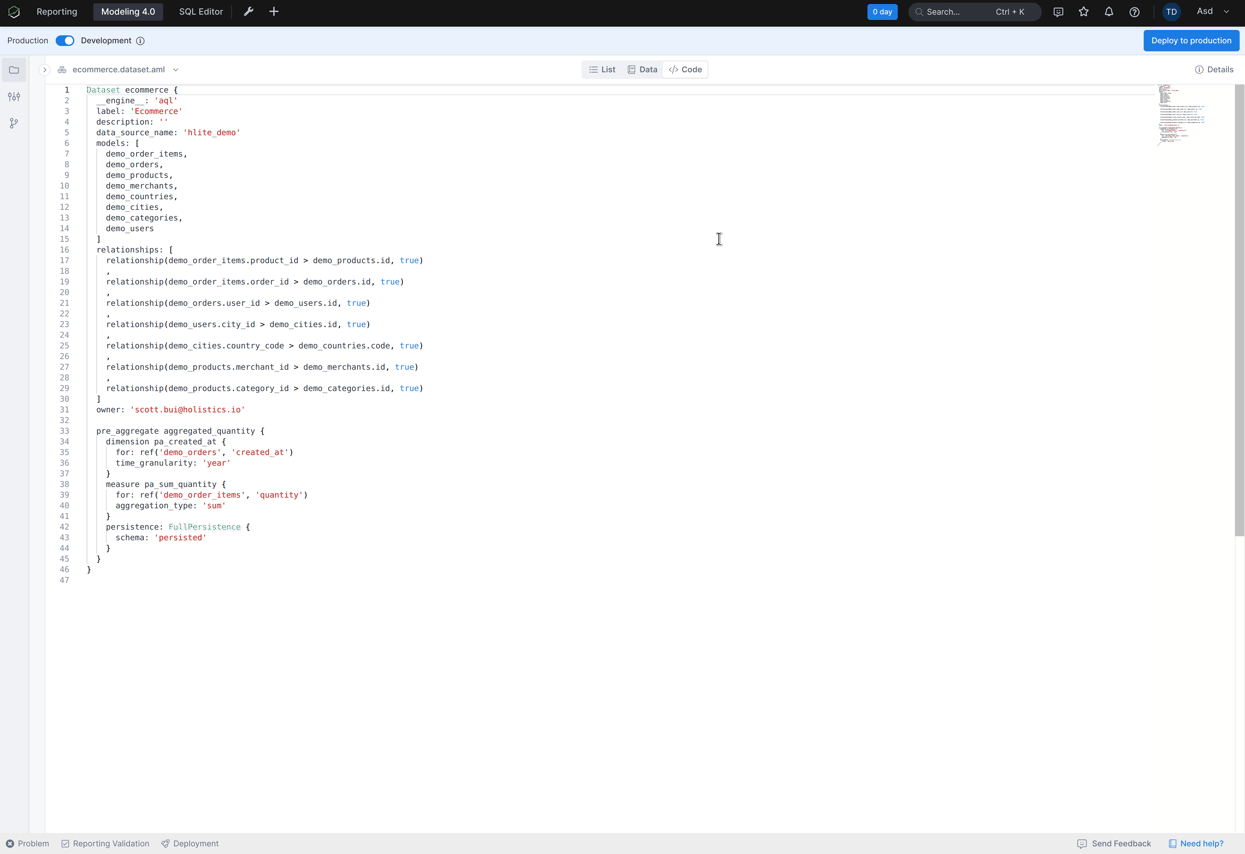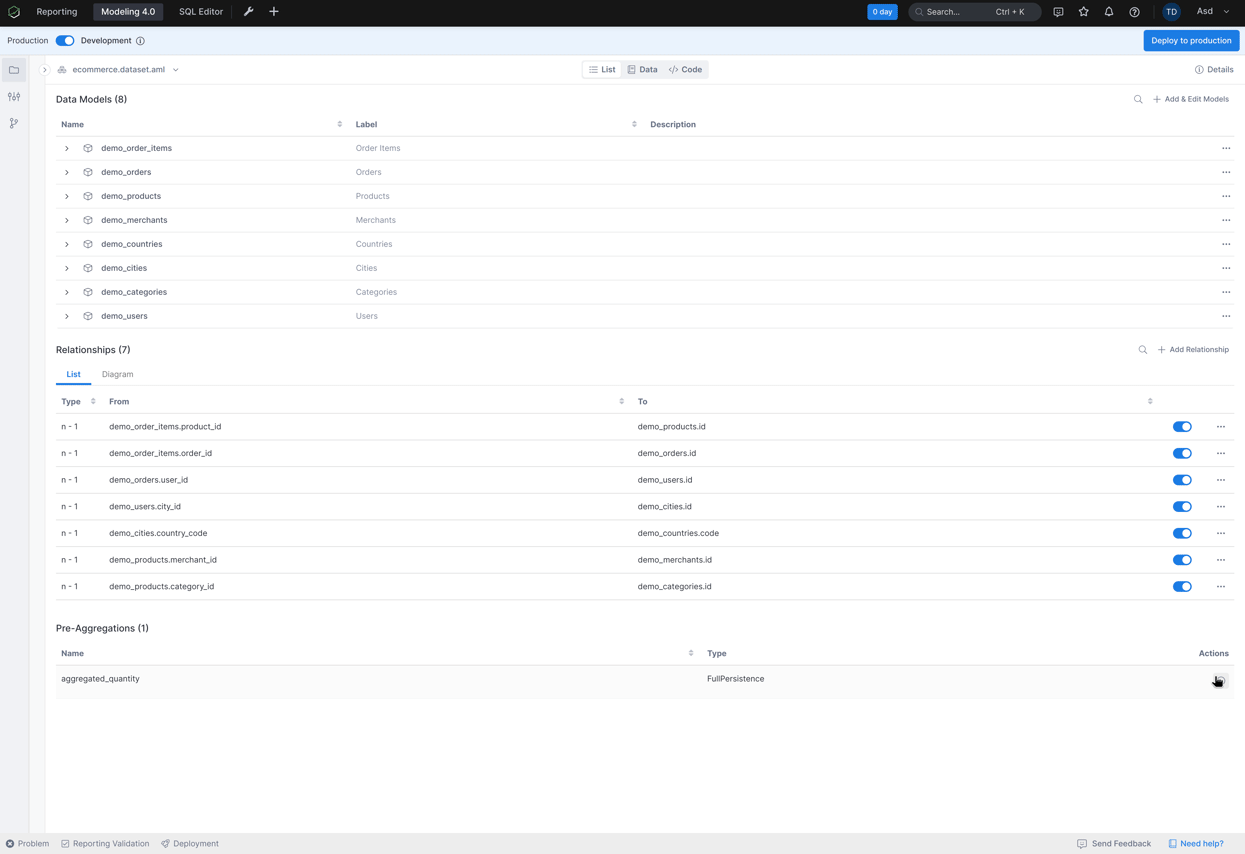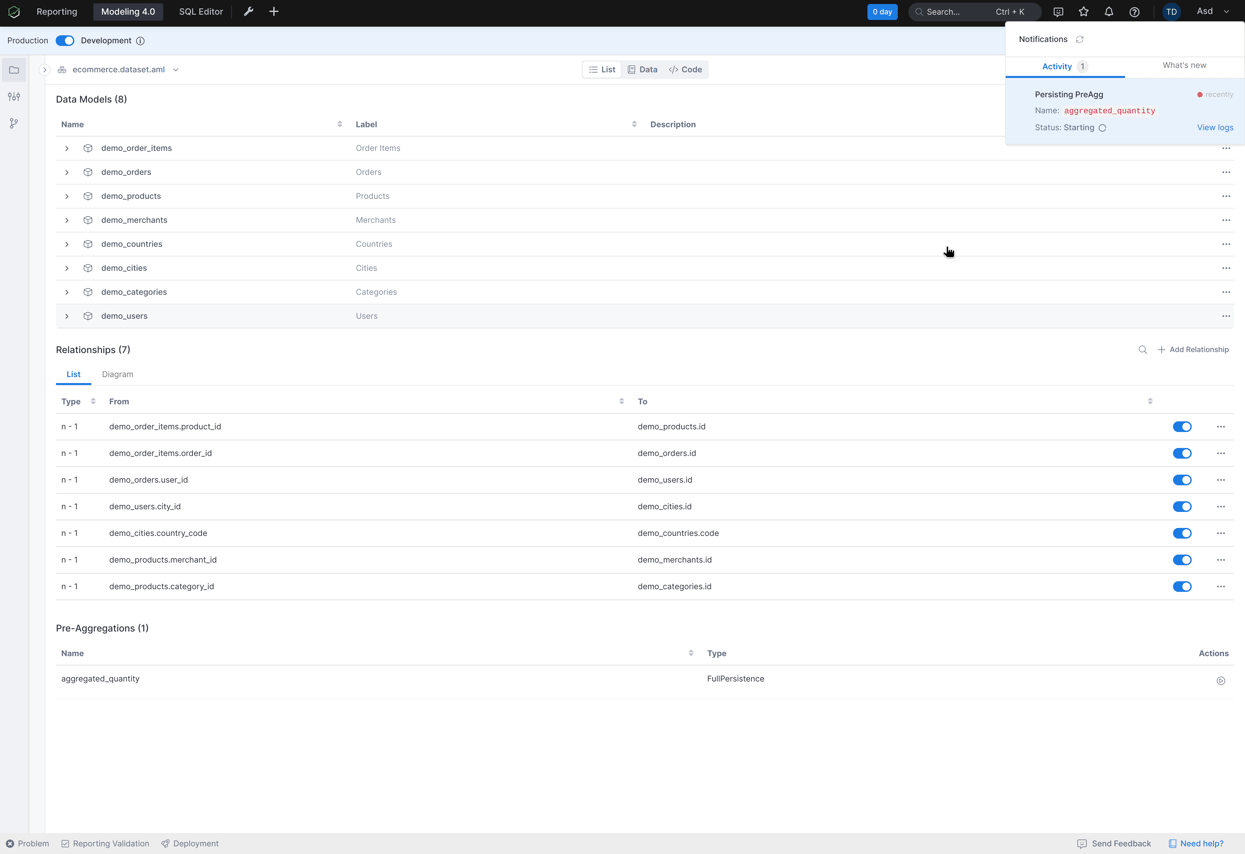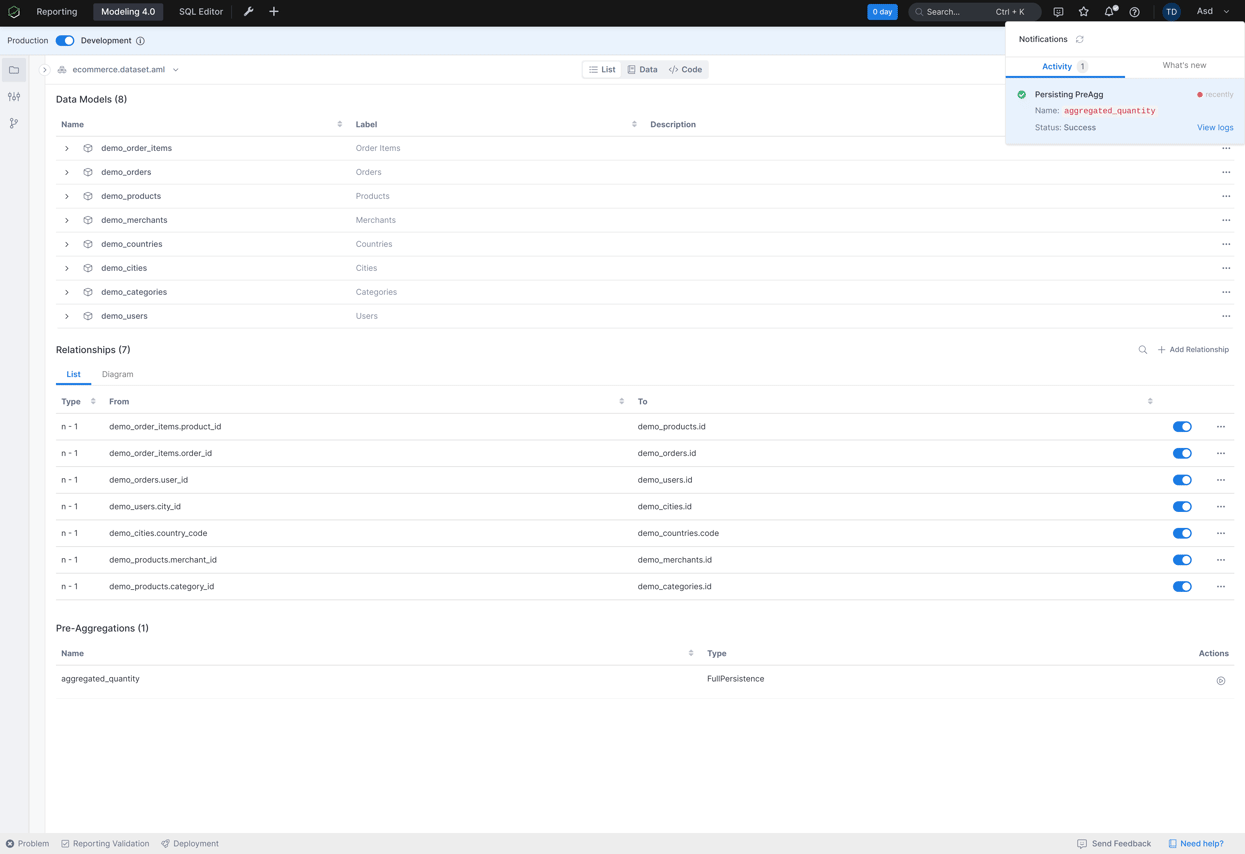
pre_aggregate aggregated_quantity_by_month {
dimension pa_created_at {
for: ref('demo_orders', 'created_at')
time_granularity: 'month'
}
measure pa_sum_quantity {
for: ref('demo_order_items', 'quantity')
aggregation_type: 'sum'
}
persistence: FullPersistence {
schema: 'persisted'
}
}
Closing Notes
We believe Aggregate Awareness will unlock analytics engineers and allow them to answer data questions much more efficiently and much faster, ultimately delivering better experience to end users.
To receive updates (or even Beta version) early, please fill in this Early Interest Form.
Kindly note that Aggregate Awareness will only be available in Datasets that use AQL engine.
If you have any questions, feel free to let us know! ![]()
p/s the above tutorial page and its screenshots are all taken from a functional version in our development environment. So you can expect this to be released soon! ![]()