I’m curious how I should approach modeling a drill-across situation in Holistics. Below describes a simplified version of what I have and the output I want.
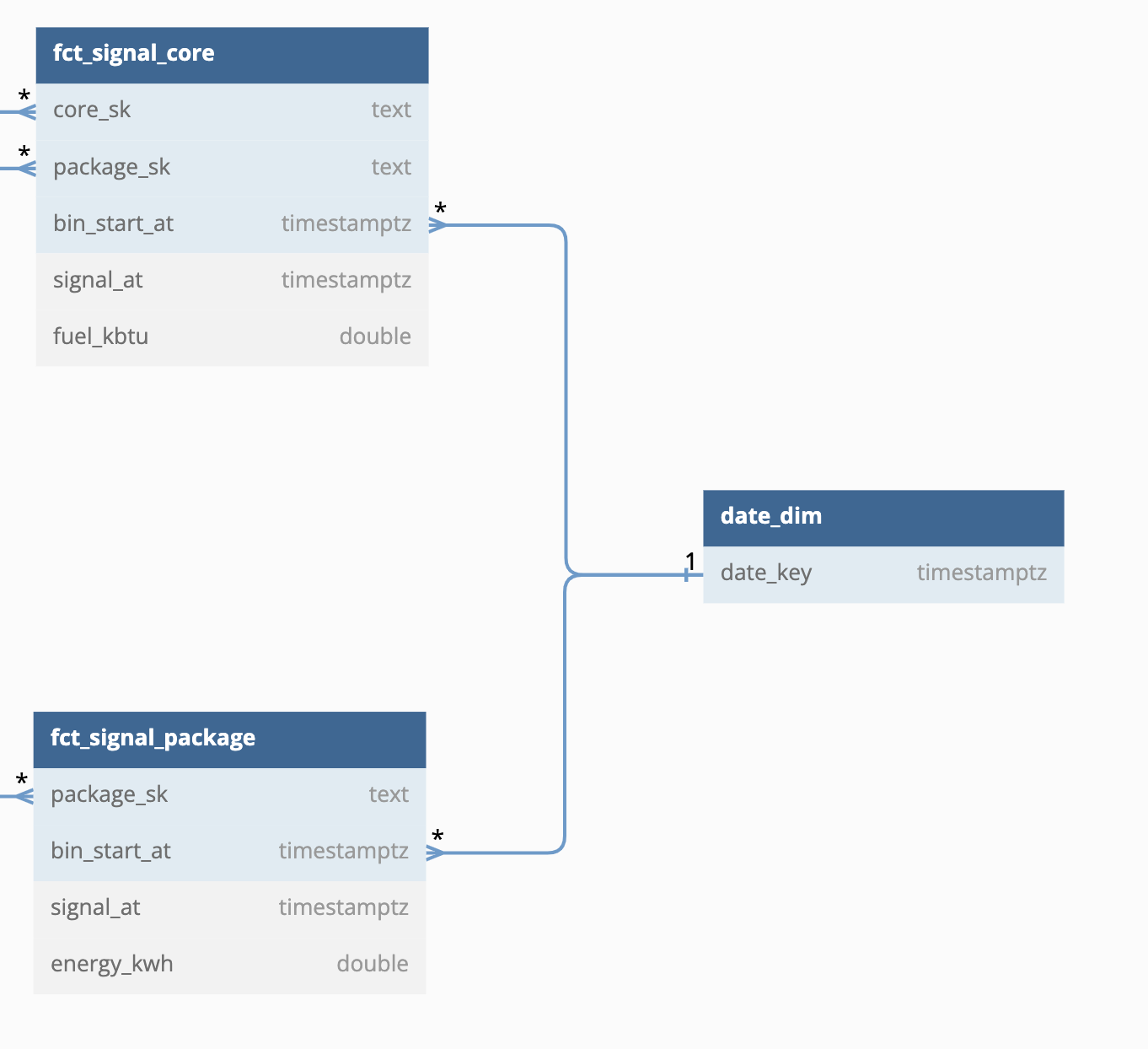
My company builds “packages” that generate electricity. Each package may consist of multiple cores, which each consume fuel independently. I have a dimensional model consisting of:
-
dim_package- A dimension containing various attributes describing packages. -
dim_core- A dimension containing various attributes describing cores. -
fct_signal_package- A fact table containing telemetry signals - one per package per point in time. Points in time have been put into standardized 15-minute “time bins”, but there can be multiple
signals per bin. -
fct_signal_core- A fact table containing telemetry signals - one per core per point in time. Points in time have been put into standardized 15-minute “time bins”, but there can be multiple signals per bin.
I want to create a time-series report showing the energy-to-fuel ratio. So I might have data that looks like this (very simplified):
dim_package - Just one package with a surrogate key and serial number:
| package_sk | package_sn |
|---|---|
| pkg1 | P1 |
dim_core - Two cores belonging to one package with a surrogate key and serial number:
| core_sk | core_sn |
|---|---|
| core1a | C1A |
| core1b | C1B |
fct_signal_package - Signal telemetry measuring energy produced by the package (signal_at is the time the signal was recorded, bin_start_at is the start of a 15-minute interval):
| package_sk | bin_start_at | signal_at | energy_kwh |
|---|---|---|---|
| pkg1 | 2022-01-01 00:00:00 | 2022-01-01 00:00:01 | 10.0 |
| pkg1 | 2022-01-01 00:15:00 | 2022-01-01 00:15:01 | 5.0 |
| pkg1 | 2022-01-01 00:15:00 | 2022-01-01 00:18:01 | 5.0 |
| pkg1 | 2022-01-01 00:30:00 | 2022-01-01 00:30:01 | 20.0 |
| pkg1 | 2022-01-01 00:45:00 | 2022-01-01 00:45:01 | 10.0 |
fct_signal_core - Signal telemetry measuring fuel consumed by the core:
| core_sk | package_sk | bin_start_at | signal_at | fuel_kbtu |
|---|---|---|---|---|
| core1a | pkg1 | 2022-01-01 00:00:00 | 2022-01-01 00:00:01 | 5.0 |
| core1a | pkg1 | 2022-01-01 00:15:00 | 2022-01-01 00:15:01 | 5.0 |
| core1a | pkg1 | 2022-01-01 00:30:00 | 2022-01-01 00:30:01 | 12.0 |
| core1a | pkg1 | 2022-01-01 00:45:00 | 2022-01-01 00:45:01 | 5.0 |
| core1b | pkg1 | 2022-01-01 00:00:00 | 2022-01-01 00:00:01 | 5.0 |
| core1b | pkg1 | 2022-01-01 00:15:00 | 2022-01-01 00:15:01 | 5.0 |
| core1b | pkg1 | 2022-01-01 00:30:00 | 2022-01-01 00:30:01 | 8.0 |
| core1b | pkg1 | 2022-01-01 00:45:00 | 2022-01-01 00:45:01 | 5.0 |
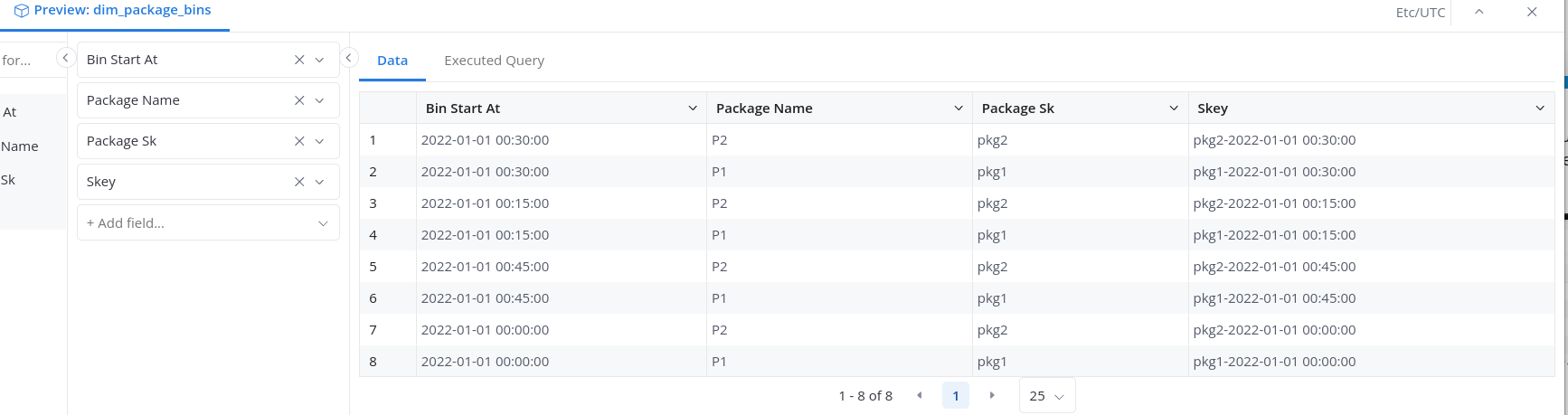
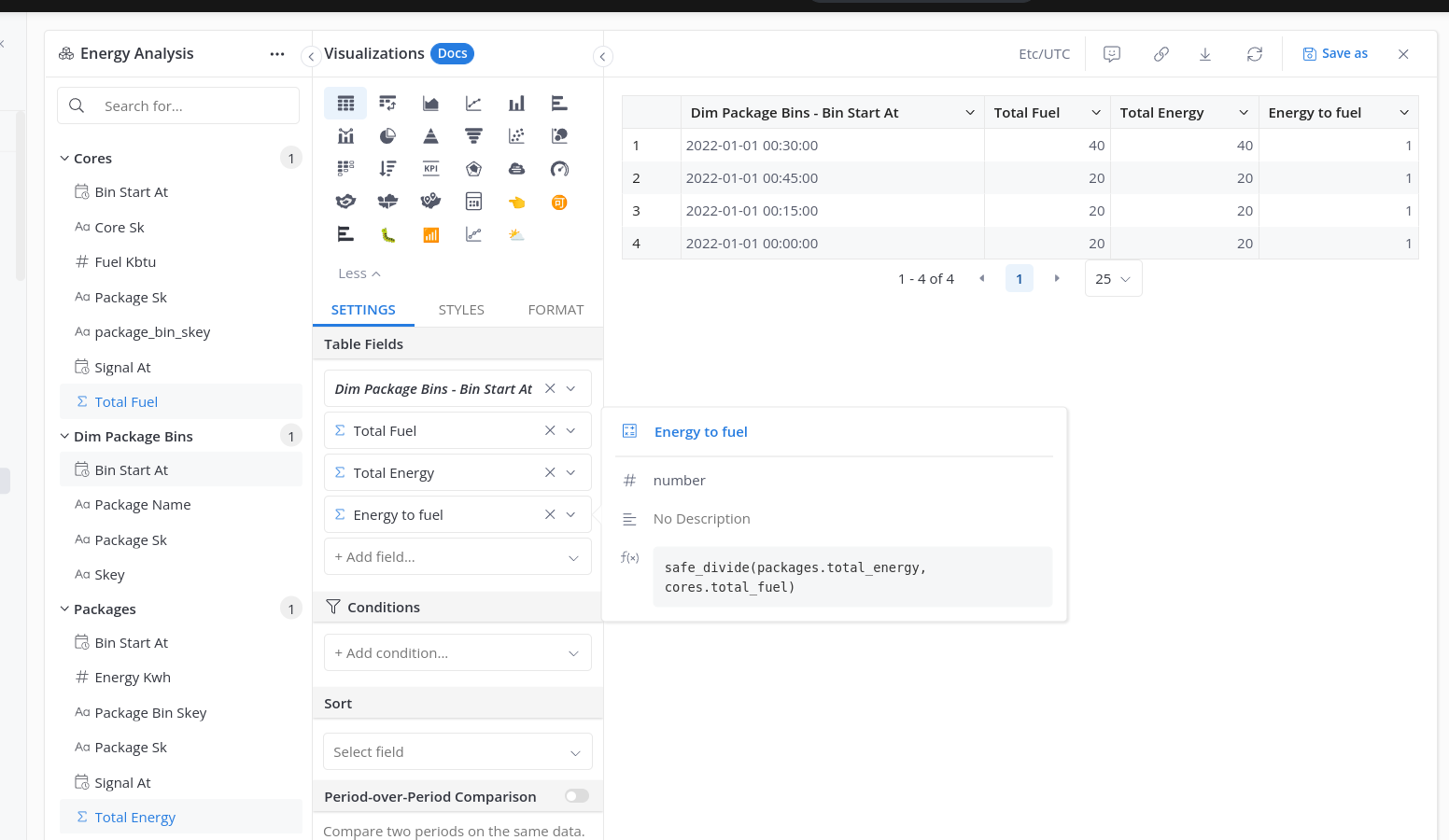
In my report, I want the average package energy-to-fuel ratio by time (data has been fabricated to give a constant ratio):
| package_sn | bin_start_at | energy_to_fuel |
|---|---|---|
| P1 | 2022-01-01 00:00:00 | 1.0 |
| P1 | 2022-01-01 00:15:00 | 1.0 |
| P1 | 2022-01-01 00:30:00 | 1.0 |
| P1 | 2022-01-01 00:45:00 | 1.0 |
I know how to write a SQL query for this: I take each of my facts, aggregate them up to the package-bin granularity, then join the results together (viola, drill-across). Something like this (Snowflake dialect):
with dim_package as (
select 'pkg1' as package_sk, 'P1' as package_sn
),
dim_core as (
select 'core1a' as core_sk, 'C1A' as core_sn
union all
select 'core1b' as core_sk, 'C1B' as core_sn
),
fct_signal_package as (
select 'pkg1' as package_sk, '2022-01-01 00:00:00'::timestamp as bin_start_at, '2022-01-01 00:00:01'::timestamp as signal_at, 10.0 as energy_kwh
union all
select 'pkg1' as package_sk, '2022-01-01 00:15:00'::timestamp as bin_start_at, '2022-01-01 00:15:01'::timestamp as signal_at, 5.0 as energy_kwh
union all
select 'pkg1' as package_sk, '2022-01-01 00:15:00'::timestamp as bin_start_at, '2022-01-01 00:18:01'::timestamp as signal_at, 5.0 as energy_kwh
union all
select 'pkg1' as package_sk, '2022-01-01 00:30:00'::timestamp as bin_start_at, '2022-01-01 00:30:01'::timestamp as signal_at, 20.0 as energy_kwh
union all
select 'pkg1' as package_sk, '2022-01-01 00:45:00'::timestamp as bin_start_at, '2022-01-01 00:45:01'::timestamp as signal_at, 10.0 as energy_kwh
),
fct_signal_core as (
select 'core1a' as core_sk, 'pkg1' as package_sk, '2022-01-01 00:00:00'::timestamp as bin_start_at, '2022-01-01 00:00:01'::timestamp as signal_at, 5.0 as fuel_kbtu
union all
select 'core1a' as core_sk, 'pkg1' as package_sk, '2022-01-01 00:15:00'::timestamp as bin_start_at, '2022-01-01 00:15:01'::timestamp as signal_at, 5.0 as fuel_kbtu
union all
select 'core1a' as core_sk, 'pkg1' as package_sk, '2022-01-01 00:30:00'::timestamp as bin_start_at, '2022-01-01 00:30:01'::timestamp as signal_at, 12.0 as fuel_kbtu
union all
select 'core1a' as core_sk, 'pkg1' as package_sk, '2022-01-01 00:45:00'::timestamp as bin_start_at, '2022-01-01 00:45:01'::timestamp as signal_at, 5.0 as fuel_kbtu
union all
select 'core1b' as core_sk, 'pkg1' as package_sk, '2022-01-01 00:00:00'::timestamp as bin_start_at, '2022-01-01 00:00:01'::timestamp as signal_at, 5.0 as fuel_kbtu
union all
select 'core1b' as core_sk, 'pkg1' as package_sk, '2022-01-01 00:15:00'::timestamp as bin_start_at, '2022-01-01 00:15:01'::timestamp as signal_at, 5.0 as fuel_kbtu
union all
select 'core1b' as core_sk, 'pkg1' as package_sk, '2022-01-01 00:30:00'::timestamp as bin_start_at, '2022-01-01 00:30:01'::timestamp as signal_at, 8.0 as fuel_kbtu
union all
select 'core1b' as core_sk, 'pkg1' as package_sk, '2022-01-01 00:45:00'::timestamp as bin_start_at, '2022-01-01 00:45:01'::timestamp as signal_at, 5.0 as fuel_kbtu
),
agg_package as (
select
dim_package.package_sn,
fct_signal_package.bin_start_at,
sum(energy_kwh) as energy_kwh
from
fct_signal_package
inner join
dim_package
on
fct_signal_package.package_sk = dim_package.package_sk
group by
1,2
),
agg_core as (
select
dim_package.package_sn,
fct_signal_core.bin_start_at,
sum(fuel_kbtu) as fuel_kbtu
from
fct_signal_core
inner join
dim_package
on
fct_signal_core.package_sk = dim_package.package_sk
group by
1,2
),
final as (
select
coalesce(agg_package.package_sn, agg_core.package_sn) as package_sn,
coalesce(agg_package.bin_start_at, agg_core.bin_start_at) as bin_start_at,
agg_package.energy_kwh / agg_core.fuel_kbtu as energy_to_fuel
from
agg_package
inner join
agg_core
on
-- Join on common dimensions - note that `bin_start_at` is a degenerate dimension
agg_package.package_sn = agg_core.package_sn
and
agg_package.bin_start_at = agg_core.bin_start_at
)
select * from final
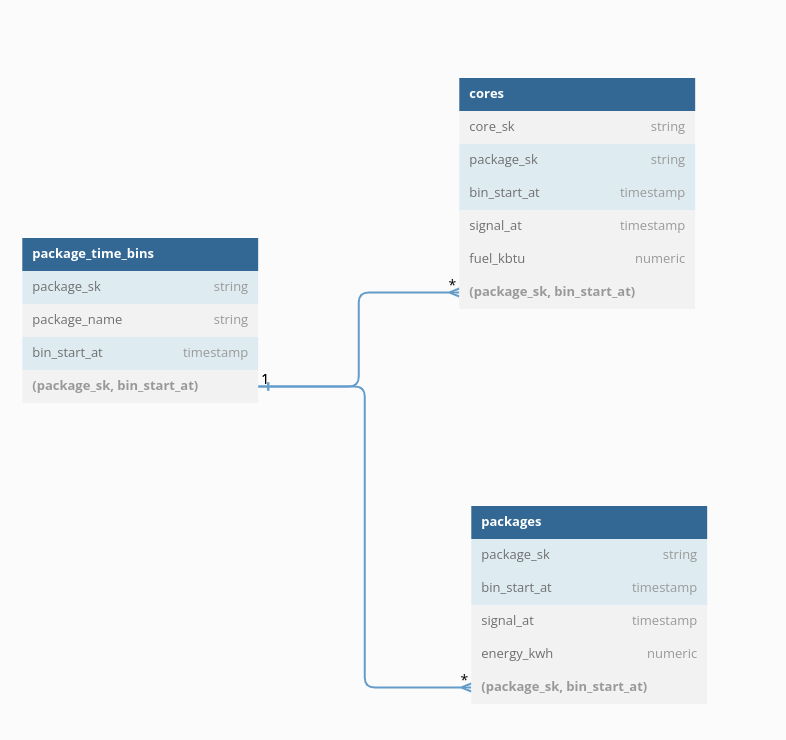
My main question here is: what is the proper way to model this kind of
relationship in Holistics? I have attempted to define the facts and dimensions as
Holistics models and include relationships between them, but unfortunately I get an error
about “Dataset contains ambiguous paths” and it makes me concerned that Holistics does
not support his kind of drill-across relationship.
- Does Holistics support datasets with multiple facts that can be combined via a Kimball-style
drill-across query, when the facts are at different levels of granularity but share common dimensions? - If not, what are some good alternatives? I suppose I could create an aggregate package-core-signal fact table that rolled up the base metrics to the same granularity. But of course if I do that, then I’ll basically be duplicating some of those metrics (e.g., I’ll need energy and fuel metrics in both the details facts and the aggregated fact).
- My real situation is actually a bit more complicated because I’ve got a third fact table I need to incorporate:
fct_signal_node, which contains measurements of the energy “grid” that is connected to a group (node) of packages all connected together. Would any of this approach change with 3 fact tables (if I had to create derived aggregate facts, I’d then need to create another one at the higher node granularity as well).