KNOWLEDGE CHECKPOINT
We think it would be best if you have a clear understanding of these concepts before reading this documentation:
GitHub Actions: [https://docs.github.com/en/actions/learn-github-actions/understanding-github-actions]
YAML syntax: https://www.tutorialspoint.com/yaml/yaml_introduction.htm
Holistics dbt integration (Manual process): https://docs.holistics.io/docs/dbt-integration
Holistics CLI: https://docs.holistics.io/docs/holistics-cli
Holistics API: https://docs.holistics.io/api
To get dbt’s metadata into Holistics, we have to manually upload the manifest.json file using Holistics CLI. This is described in details here.
To automate this process, we can integrate it as part of a CI/CD workflow such as Github Actions.
Prerequisites
- We will assume that you are already familiar with the tools mentioned in this guide. Refer to
Knowledge Checkpointbox at the top of the guide for the list of necessary concepts/ tools. - You must already have a working dbt project, with valid database credentials. In this guide, we will use BigQuery, but the approach remains the same with other databases
- You must already have a Holistics API Token. If you are unsure how, please refer to this document.
Outcome
Upon reading this guide, you should be able to create a Github Actions workflow that generates manifest.json file from the main/master branch of your dbt project, and uploads this file to Holistics using Holistics CLI. This workflow can be triggered:
- manually
- with a fixed schedule
- or by a Pull Request’s
mergeevent.
Step-by-step Guide
Example of a dbt profile that we use this guide:
Click to open
holistics-bigquery:
target: prod
outputs:
prod:
type: bigquery
method: service-account
project: <your-bq-project-name>
dataset: dbt
threads: 32
timeout_seconds: 300
priority: interactive
keyfile: "specify_your_keyfile_path_here"
You can either use Service Account File by specifying a keyfile or use Service Account JSON on production environment.
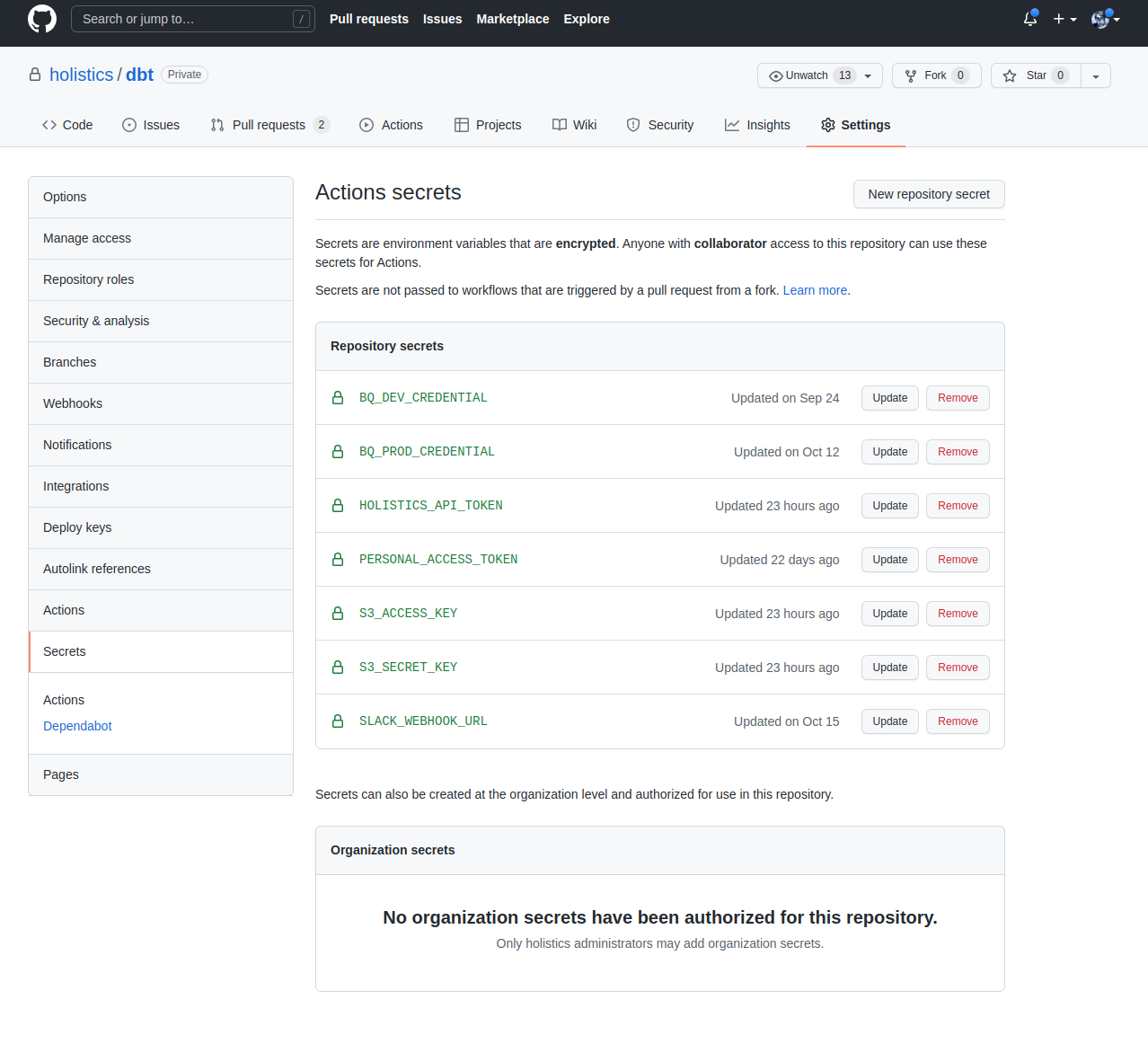
Prepare necessary credentials with Action secrets
To use sensitive data like credentials in a workflow, the recommended way is to create and store them as Action secrets. Refer to this guide for more information.
Below is the list of credentials required for this workflow:
- Your data-warehouse credentials.
- Holistics API Token. This is used to authenticate your requests to Holistics. Read more about them here.
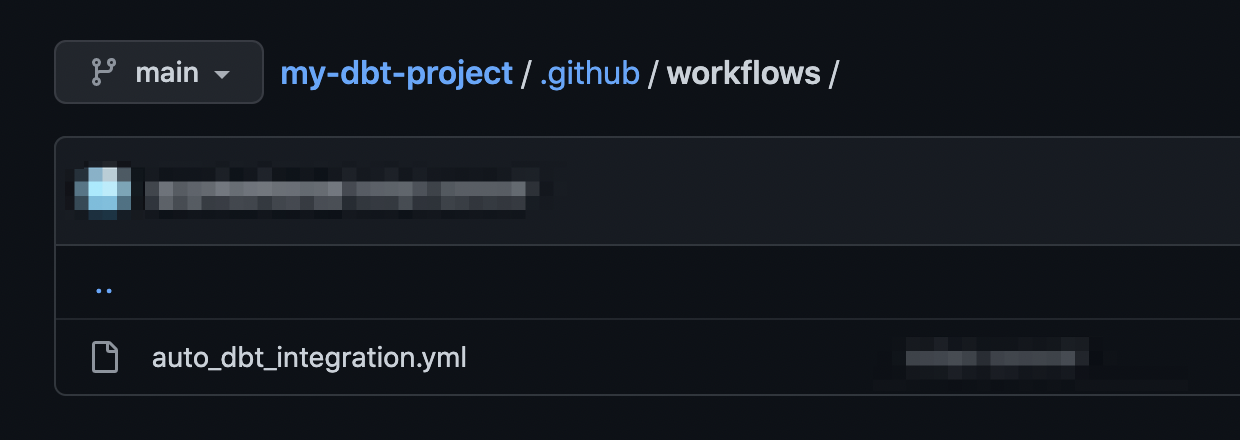
Create your workflow file
- In your repository, create the
.github/workflows/directory to store your workflow files. - In the
.github/workflows/directory, create a new file calledauto_dbt_integration.yml. Let’s define our workflow in this file.
Define the basic information for your workflow
name: Update dbt project state
on:
schedule:
- cron: '0 0 */2 * *'
workflow_dispatch:
jobs:
update-project-state:
runs-on: ubuntu-20.04
env:
DBT_PROFILES_DIR: ./dbt_profiles
HOLISTICS_API_TOKEN: ${{ secrets.HOLISTICS_API_TOKEN }}
BQ_DEV_CREDENTIAL: ${{ secrets.BQ_DEV_CREDENTIAL }}
ImageOS: ubuntu20 # Environment variable required by setup-ruby
This part lets you define the display name of the workflow, and events that trigger it.
In our code snippet, we have:
- (Optional)
name: Specify name of this workflow on: Specify the triggers for this workflow. We have two triggers:schedule: This workflow will be triggered on a schedule defined with cron syntax.workflow_dispatch: This workflow will be triggered manually. For more information, check out this documentation.
jobs: A workflow needs at least one job.- The job is named
updated-project-state. runs-on: Its runner usesubuntu-20-04 OS. To learn more about runner, click here.- Under the
envkey are the environment variables:- DBT_PROFILES_DIR: In your dbt repository, there should be a directory containing the
profiles.ymlfile. Specify the directory path here. - HOLISTICS_API_TOKEN: If you have defined this credentials in Preparation task, simply reference it here with this syntax
${{ secrets.HOLISTICS_API_TOKEN}} - BQ_DEV_CREDENTIAL: If you have defined this credentials in Preparation task, simply reference it here with this syntax:
${{ secrets.BQ_DEV_CREDENTIAL }} - ImageOS: This is an environment variable required by the
setup-rubystep. Value of this shoud match the OS of the runner.
- DBT_PROFILES_DIR: In your dbt repository, there should be a directory containing the
- The job is named
Now that we have the prerequisites, it’s time to write the job definition.
Write step definitions for your job
A job will consist of multiple steps. Let’s go through each step one by one.
Step 1: Check-out code from master
Action: https://github.com/actions/checkout
- name: Checkout master
uses: actions/checkout@v2
with:
ref: master
This action will clone the dbt code from the master branch of your repo into the runner’s workspace.
Step 2: Read credentials from secret
- name: Read BigQuery credentials from secret
run: |
echo "$BQ_DEV_CREDENTIAL" | base64 -d -i > dbt_profiles/cred.json;
In this step, we echo the value of the env var BQ_DEV_CREDENTIAL into a JSON file, so that the dbt profile can read it.
Notes:
- We are using Service Account file authentication method with a JSON key file. If you are configure this in a production environment, opt for Service Account JSON instead.
- The
base 64 -d -icommand is needed because the original JSON string is encoded usingbase64before storing in secrets.
Step 3: Setting up Ruby & Holistics CLI
Action: https://github.com/marketplace/actions/setup-ruby-jruby-and-truffleruby
- name: Install libyaml
run: |
wget https://pyyaml.org/download/libyaml/yaml-0.2.5.tar.gz;
tar xzvf yaml-0.2.5.tar.gz;
cd yaml-0.2.5;
./configure --prefix=/usr/local;
make;
sudo make install;
- name: Set up Ruby
uses: ruby/setup-ruby@v1
with:
ruby-version: 2.7.4
Before setting up Ruby, we need to install libyaml to the runner or the process will fail with an error:
warning: It seems your ruby installation is missing psych (for YAML output). To eliminate this warning, please install libyaml and reinstall your ruby.
After that, install Holistics gem. This step can be placed anywhere after the setup ruby step.
- name: Install Holistics CLI
run: |
gem install holistics;
Step 4: Setting up Python & dbt
Action: https://github.com/marketplace/actions/setup-python
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: 3.7
After that, set up dbt:
- name: Set up dbt
run: |
pip3 install dbt-bigquery;
dbt deps;
Since version 1.0.0, you will need to specify the dbt adapter when installing. pip3 install dbt-bigquery will install dbt-core, along with the dependencies for dbt to run on BigQuery.
You will also need to run dbt deps to install packages needed in the dbt project.
Step 5: Generate dbt manifest file & upload to Holistics
The next step is to create the manifest.json file and upload it to Holistics.
- name: Generate manifest file for prod target & upload to S3
shell: bash
run: |
dbt compile --no-version-check -t prod;
- name: Upload manifest file to staging-internal
run: |
holistics login $HOLISTICS_API_TOKEN
holistics dbt upload --file-path ./target/manifest.json --data-source=your_dbt_database_name
Notes:
-
dbt’s
manifest.jsonfile can be generated by several dbt’s commands, butdbt compileis the fastest and safest one to use. The command only parses the project and compiles dbt models into normal SQL files and nothing would be written to your database.The manifest file will be created at path
./target/manifest.json -
It is important that the
--data-sourcematches the database of the dbt target you use to generate the manifest file.In this case, the
prodtarget and theyour_dbt_database_namedata source both refer to the same BigQuery project. In fact, they both use the same Service Account file.
(Optional)Trigger workflow when a Pull Request is merged
In case you want your Holistics AML project to always be updated with the latest metadata from dbt, you can set up the workflow to be triggered when you merge a Pull Request.
name: Update dbt project state
on:
pull_request: # Trigger workflow upon closing a PR
types: [closed]
workflow_dispatch:
jobs:
update-project-state:
# Run workflow only when the PR is closed after merging
if: github.event.pull_request.merged == true
runs-on: ubuntu-20.04
To do so, add pull_request as a trigger event. This line:
if: github.event.pull_request.merged == true
ensures the workflow is only triggered when the PR closing event comes from a merging action. Without it, if when you close a PR without merging, this workflow will be triggered.
Code Example
Example of a full workflow definition:
Click to open
name: Update dbt project state
on:
schedule:
- cron: '0 0 */2 * *'
workflow_dispatch:
jobs:
update-project-state:
runs-on: ubuntu-20.04
env:
DBT_PROFILES_DIR: ./dbt_profiles
HOLISTICS_API_TOKEN: ${{ secrets.HOLISTICS_API_TOKEN }}
BQ_DEV_CREDENTIAL: ${{ secrets.BQ_DEV_CREDENTIAL }}
ImageOS: ubuntu20 # Environment variable required by setup-ruby
steps:
# Preparations
- name: Checkout master
uses: actions/checkout@v2
with:
ref: master
- name: Read BigQuery credentials from secret
run: |
mkdir -p dbt_profiles/;
echo "$BQ_DEV_CREDENTIAL" | base64 -d -i > dbt_profiles/cred.json;
shell: bash
- name: Install libyaml
run: |
wget https://pyyaml.org/download/libyaml/yaml-0.2.5.tar.gz;
tar xzvf yaml-0.2.5.tar.gz;
cd yaml-0.2.5;
./configure --prefix=/usr/local;
make;
sudo make install;
- name: Set up Ruby
uses: ruby/setup-ruby@v1
with:
ruby-version: 2.7.4
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: 3.7
- name: Set up dbt
run: |
pip3 install dbt-bigquery;
dbt deps;
- name: Install Holistics CLI
run: |
gem install holistics;
holistics version;
- name: Generate manifest file for prod target & upload to S3
shell: bash
run: |
dbt compile --no-version-check -t prod;
- name: Upload manifest file to Holistics
run: |
holistics login $HOLISTICS_API_TOKEN
holistics dbt upload --file-path ./target/manifest.json --data-source=bigquerydw