Background
When running database queries, Holistics retrieves the query results and stores them in Holistics Cache before further processing:
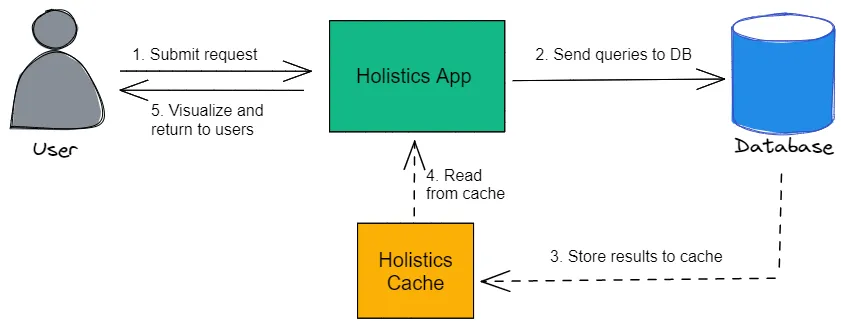
(Ref: Caching Mechanism (Cache) | Holistics Docs (4.0))
While Holistics already has existing Connector and Caching services in place (at steps 2, 3, and 4 above), the current system has several performance and scalability challenges.
Our team has spent months analyzing and optimizing the old system but some bottlenecks still remain. After further analysis, experiments, and industry research, we have decided that investing in a new system would be more beneficial to Holistics and its users in the long run.
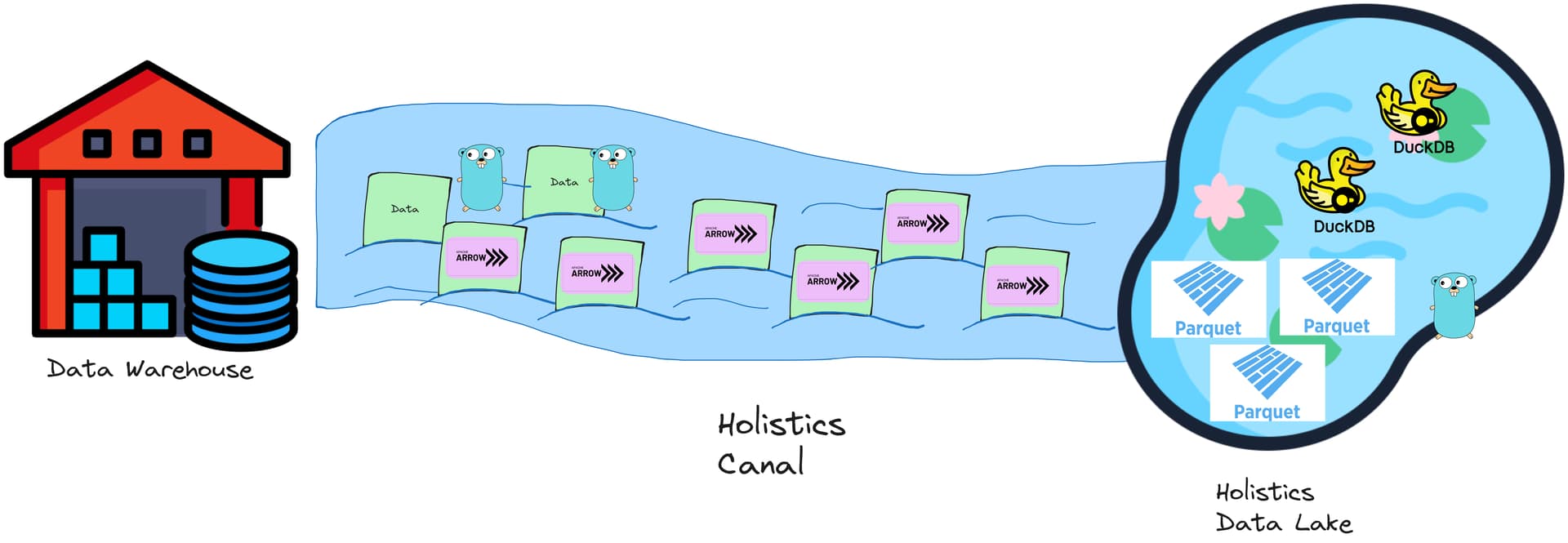
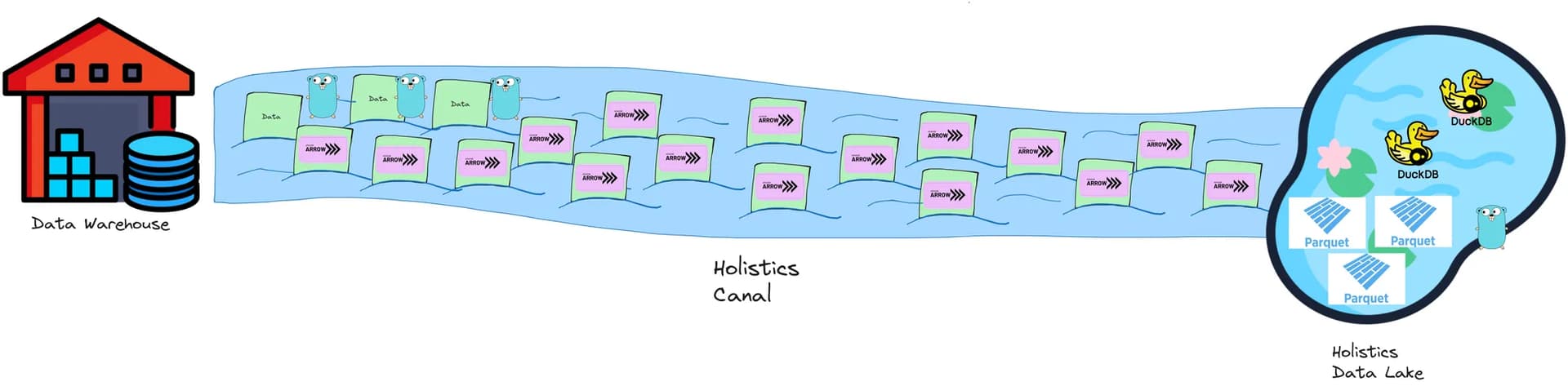
Introducing: Holistics Canal
Canal is our newly developed Connector and Caching system, which aims to provide much better performance, maintainability, and scalability throughout Holistics querying operations.
The Canal system consists of:
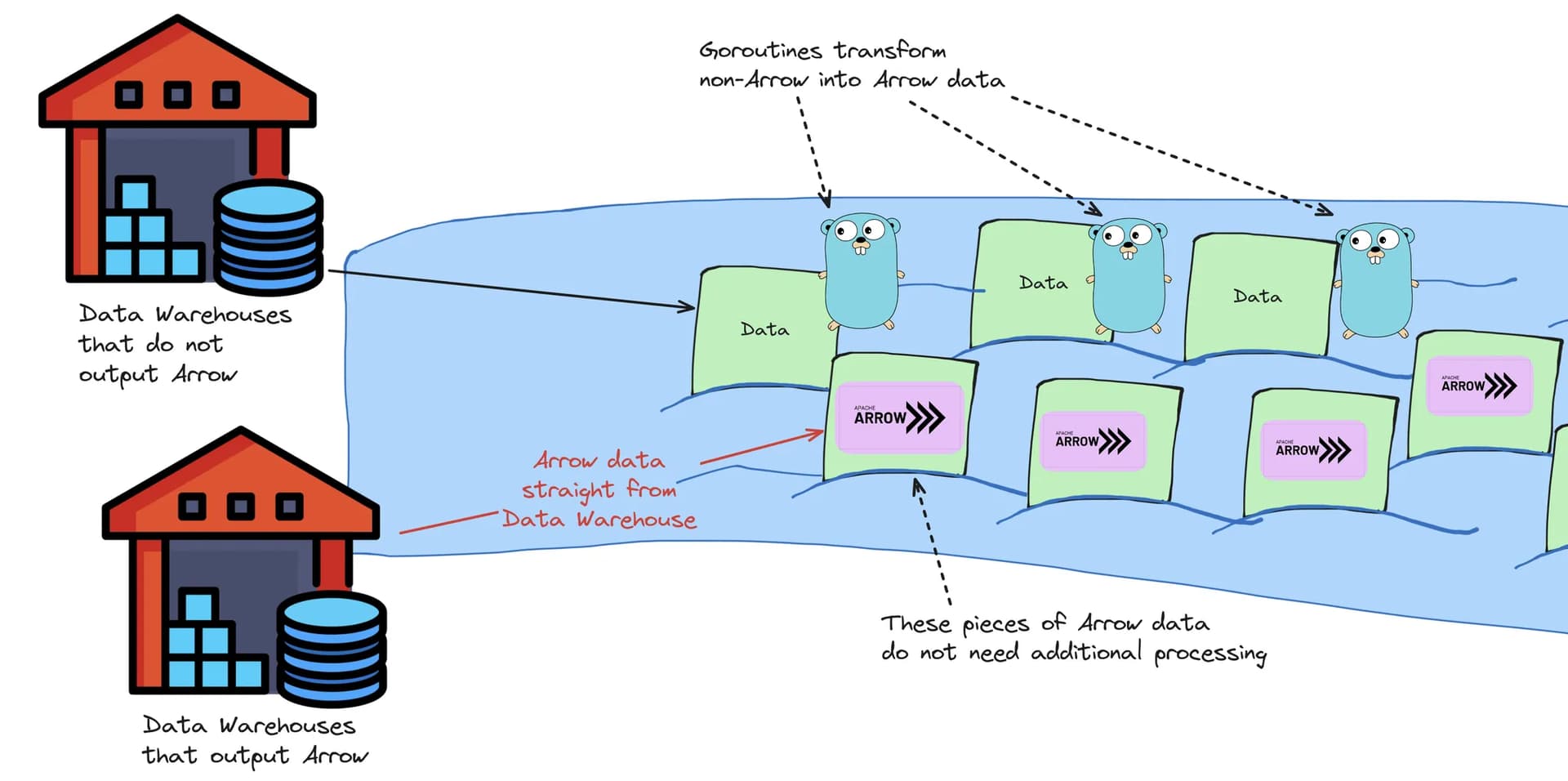
- Connector services: connect, query, and stream data from Data Warehouses (of Holistics customers) into the Data Lake.
- Caching services (aka. Data Lake): provides queryable cache storage.
The new Canal system provides significant advantages over the current system. In the following sections, we will discuss the advantages focusing on step 3 of Holistics Data Caching (Store results to cache) mentioned in the Background above.
Streaming
Canal employs the data “streaming” technique that eliminates lots of overheads and bottlenecks when transferring data.
Before
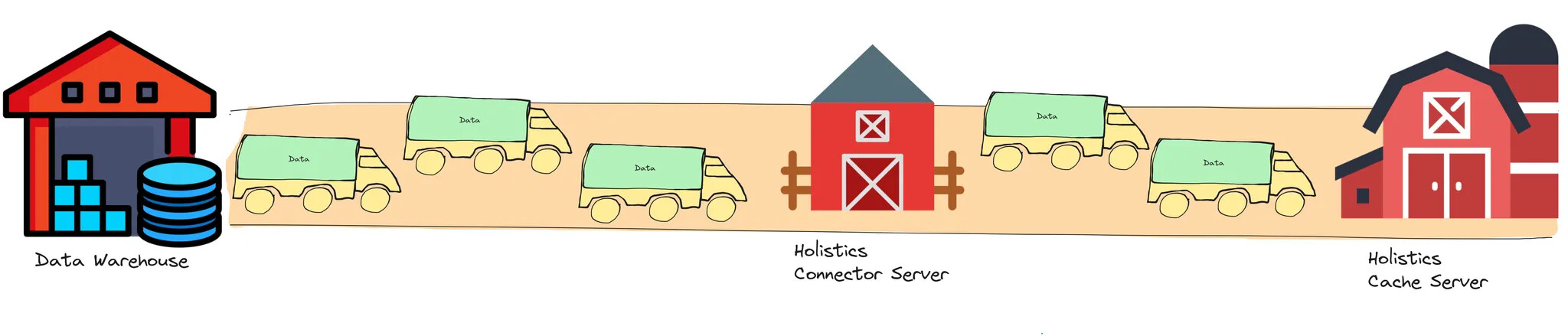
- Data is transported in bigger “trucks” (or chunks).
- The throughput is low: the road only fits a few trucks at a specific time (or road segment).
- Have to unload data into the intermediary Connector Server, then load them up onto the trucks again before transporting them to the Cache Server. This is a costly step (especially because of the concurrency issue mentioned below.
- Memory costs: the Connector Server has to carry large amounts of data in its memory.
- The memory will have to be cleaned up later (i.e. Garbage Collection) and this cleanup process also slows down the server.
- When the memory reaches the server limit, the server would slow down and might even crash.
After
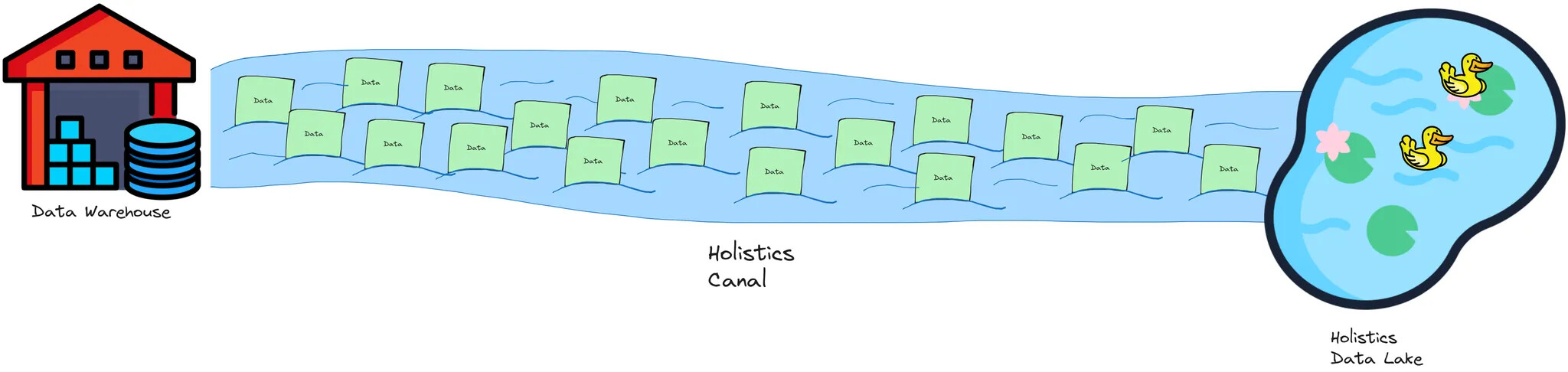
- Data “flows” as smaller “packages” or chunks through the Canal straight into the Data Lake.
- Higher throughput: the “canal” fits more packages at a time.
- No overhead of intermediary loads/unloads.
- Minimal memory costs.
Notes
- The new system does not change the network speed. Hence, in the illustrations above, the speed of the “trucks” and the speed of the “canal flow” are pretty much equivalent.
Technologies
Holistics Canal uses new great technologies, nominally:
Golang
The whole Holistics Canal system (including Data Lake) runs on Golang.
This gives many benefits to the system, including:
Faster execution
Old Holistics Connector runs on Ruby, which is an interpreted programming language. Compilations only happen during runtime (i.e. Just-in-time compilation). On the other hand, Golang compiles the code ahead of runtime, allowing the runtime to execute faster right from the get-go.
Golang also enables us to use more efficient data structures and make lower-level optimizations in our codes.
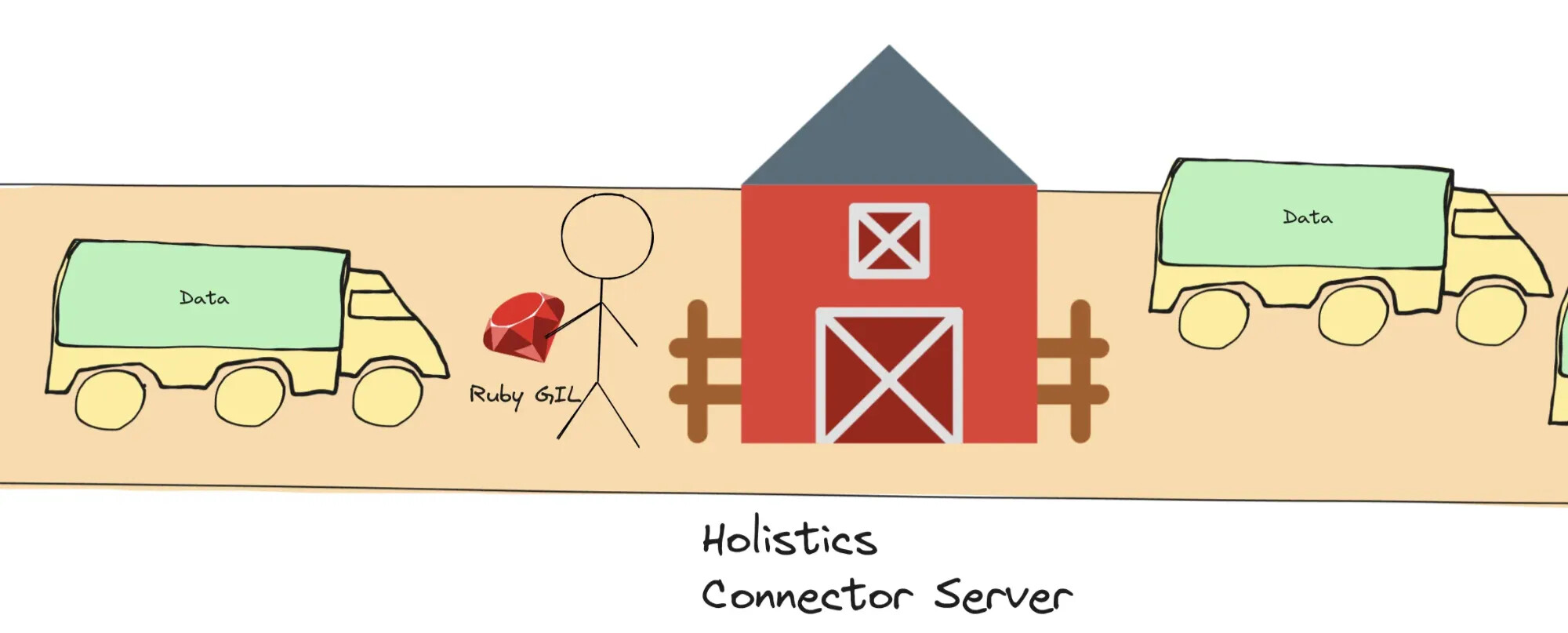
Better concurrency
Ruby has a Global Interpreter Lock (GIL) which limits the concurrency power in certain operations.
Consider the following rough analogy:
- Each “barn” (Connector Server) has a single Ruby GIL (i.e. each Connector Server is a Ruby process).
- The “worker” must hold the Ruby GIL to be permitted to unload data from the left “truck” into the “barn” and to load data into the right “truck”.
⇒ There can only be 1 worker unloading/loading data at a time, which slows down the whole pipeline.
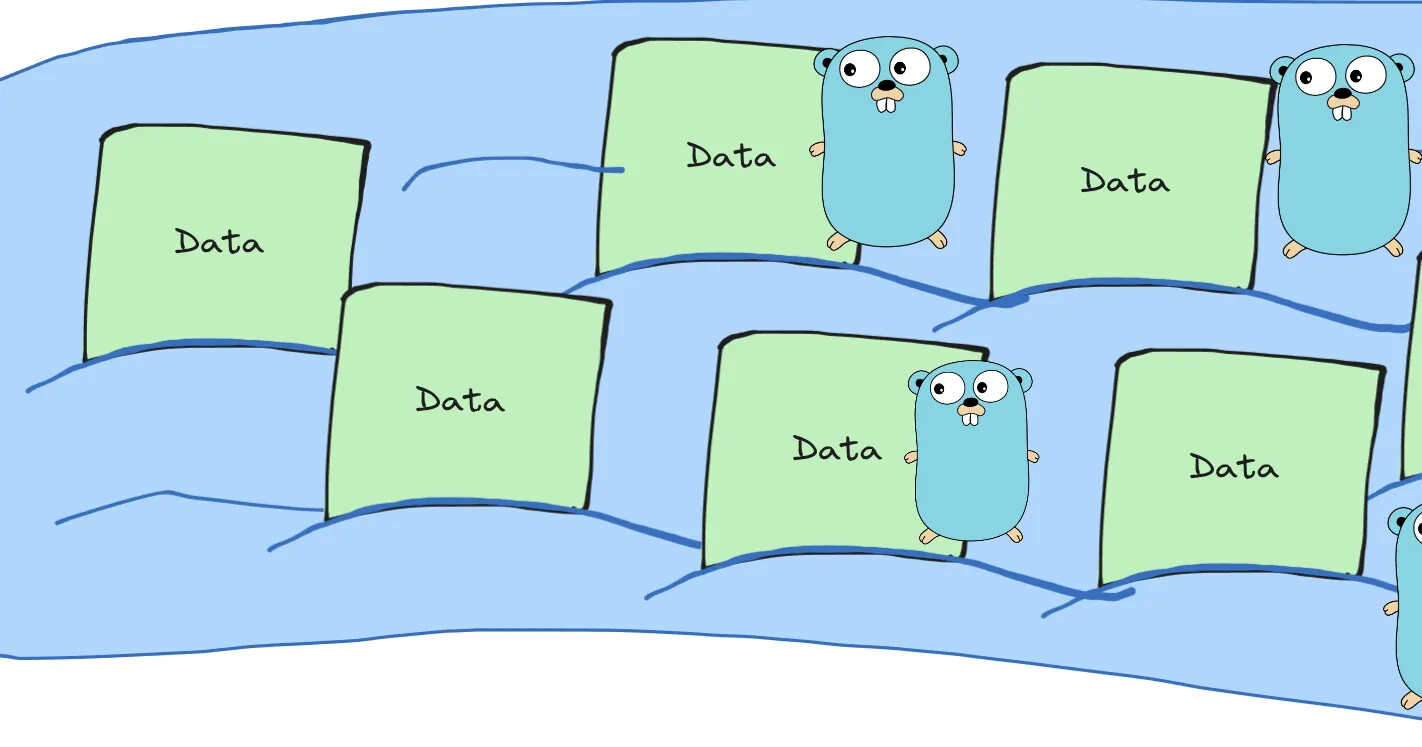
On the other hand, Golang can spawn multiple Goroutines working in parallel.
In our illustration, Golang allows us to operate on multiple “currents” at the same time, right in the middle of the flow/streaming.
Access to better data processing tools and technologies
- Golang has first-class support from major Databases/Data Warehouses. Thus, the Golang database connector libraries are often readily available, more performant, have more features, and have fewer bugs.
- Apache Arrow and Apache Parquet libraries are also very well-maintained in Golang, while they are still pretty primitive in Ruby at this moment.
Apache Arrow and Apache Parquet
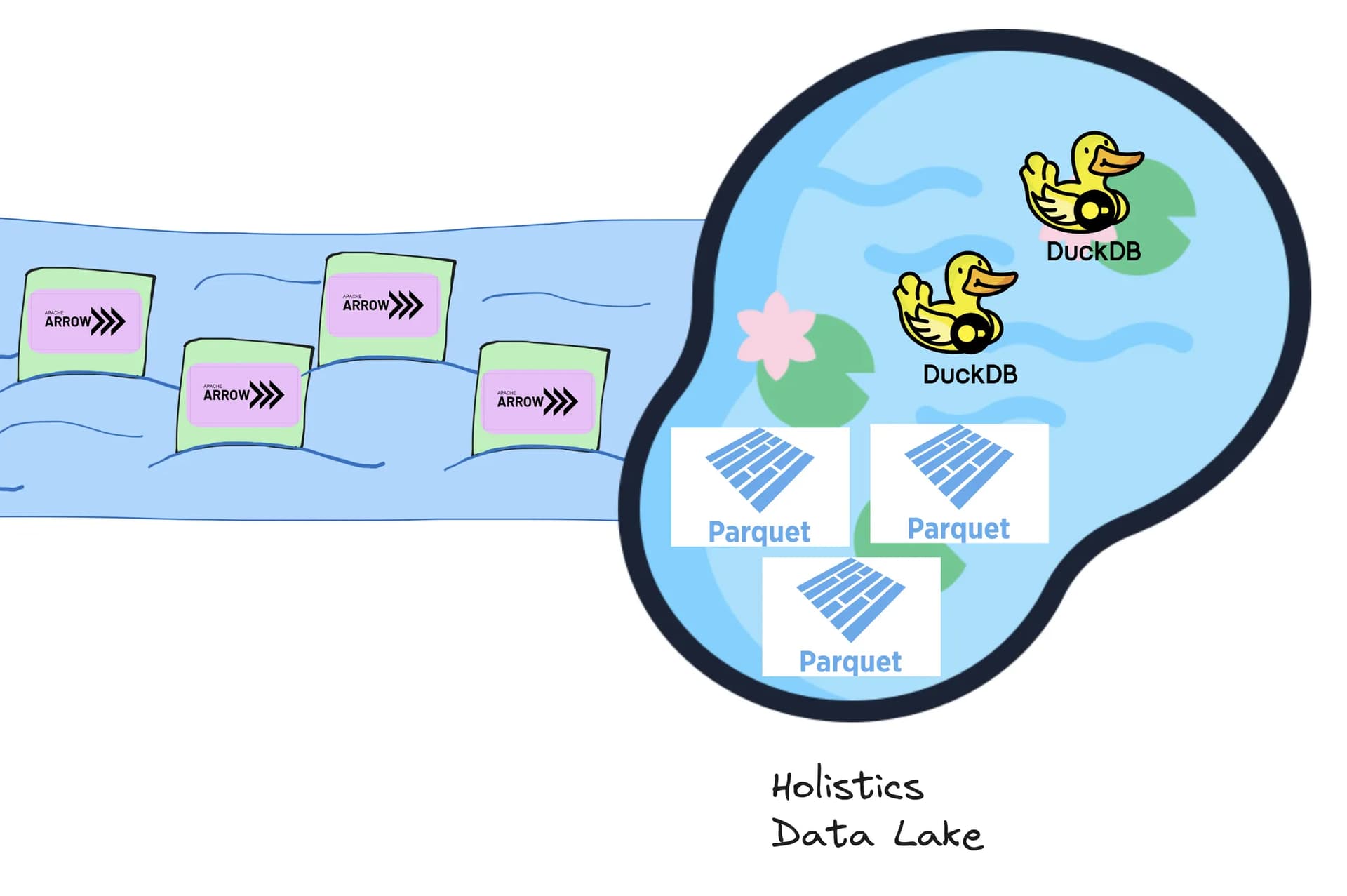
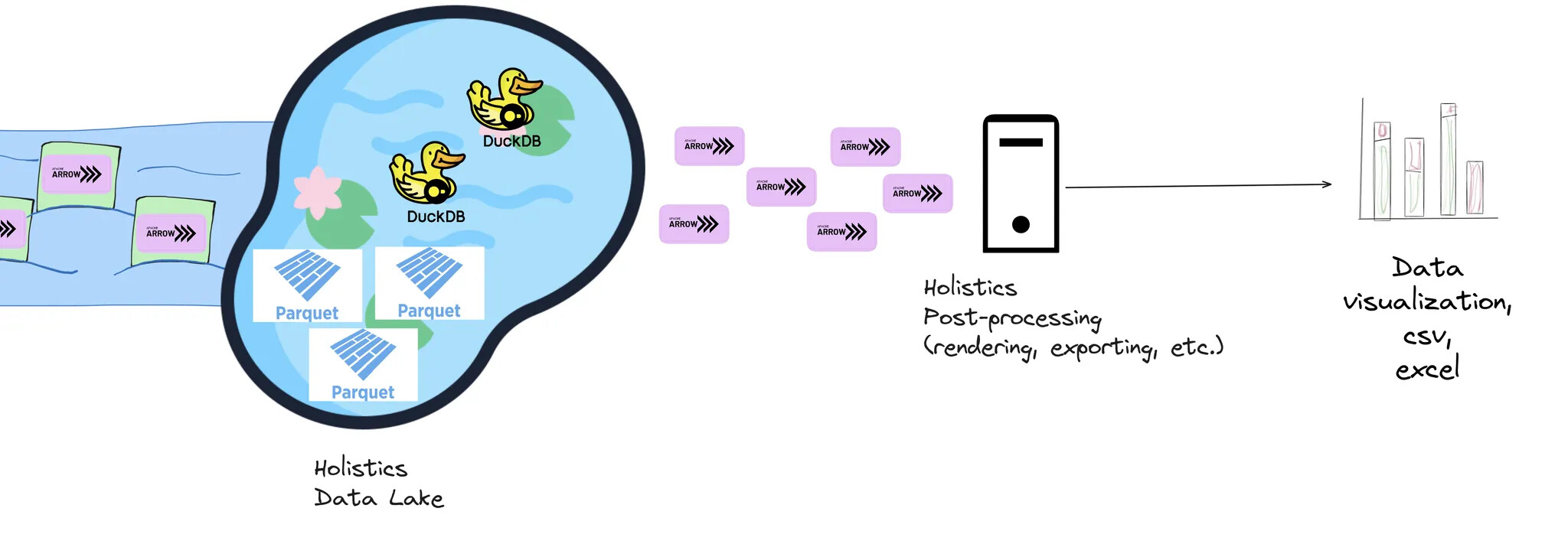
Holistics Canal uses Apache Arrow as the data format for transferring data into the Data Lake.
- It avoids the cost of “unloading” and “loading” data (i.e. serialization and deserialization) into and from the Data Lake.
- For data warehouses (e.g. BigQuery and Snowflake) that use columnar storage themselves and provide Apache Arrow as query output format, this also avoids the cost of “unloading” data from the data warehouses.
- For data warehouses (e.g. BigQuery and Snowflake) that use columnar storage themselves and provide Apache Arrow as query output format, this also avoids the cost of “unloading” data from the data warehouses.
- It can be seamlessly stored and processed as a columnar data storage, enabling fast data analytics and retrieval.
- Currently, we store the Arrow data as Apache Parquet files, which provide storage compression and portability while still being fast enough when queried by Duckdb.
Duckdb
We use Duckdb as our Cache Query Engine:
- Features: Duckdb provides lots of useful querying and analytics features.
- Speed:
- Duckdb vectorized query execution model allows high-performance querying on cached data.
- Duckdb can output Arrow data, which again is very efficient when transferring to post-processing services.
Future
As the tools and technologies around Apache Arrow and Duckdb are evolving every day, we can expect to incorporate more features into Holistics and improve Holistics performance even further in the future!
Benchmarks
Below are the benchmarking results when querying 10 Holistics reports concurrently from a Postgresql database into Holistics cache.
- Querying 10 reports concurrently means we query 10 reports at a time on a single server.
- Each report contains 5 columns, and we run it with different number of row limits. For each number of rows, we run the benchmark 5 times.
- This benchmark is conducted in our development environment.
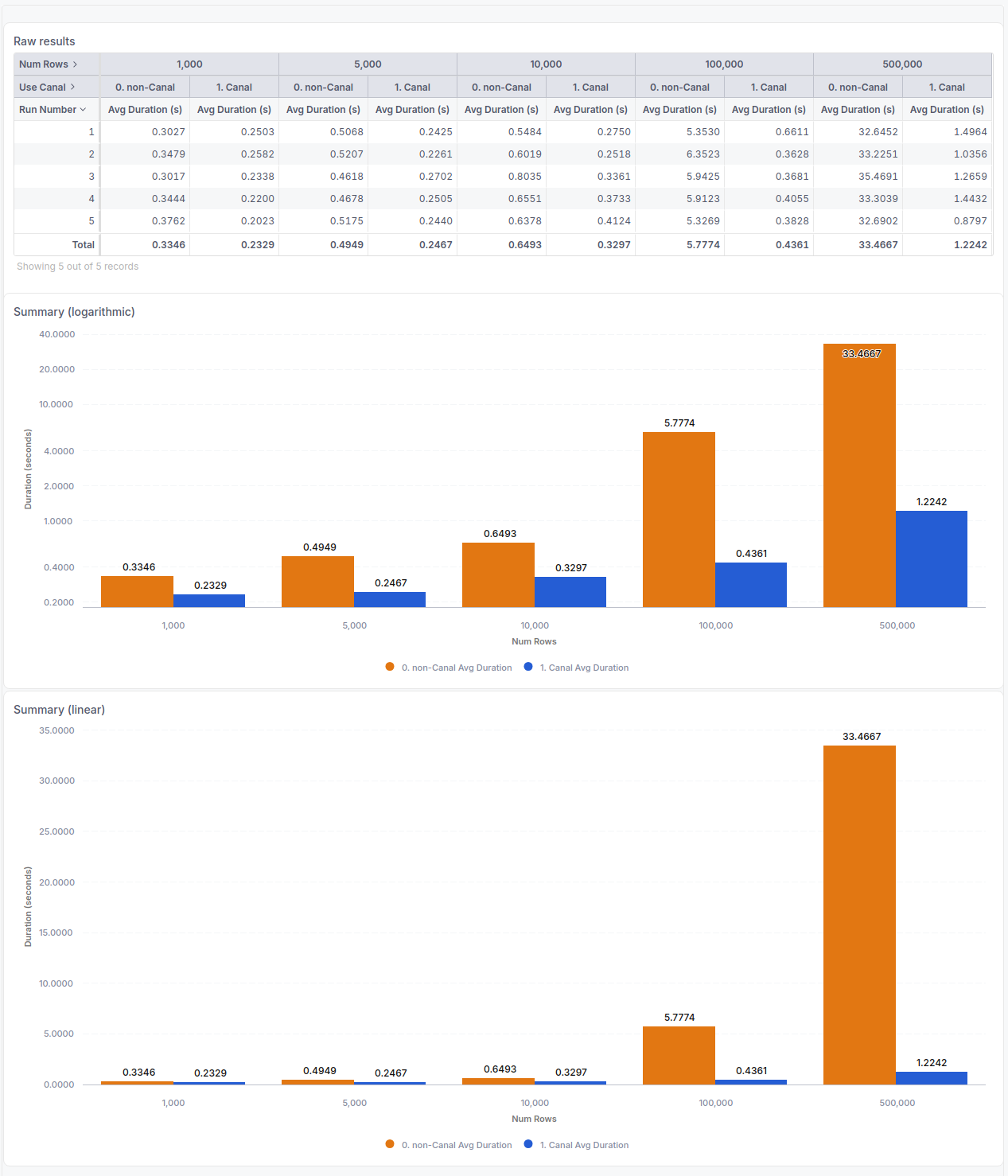
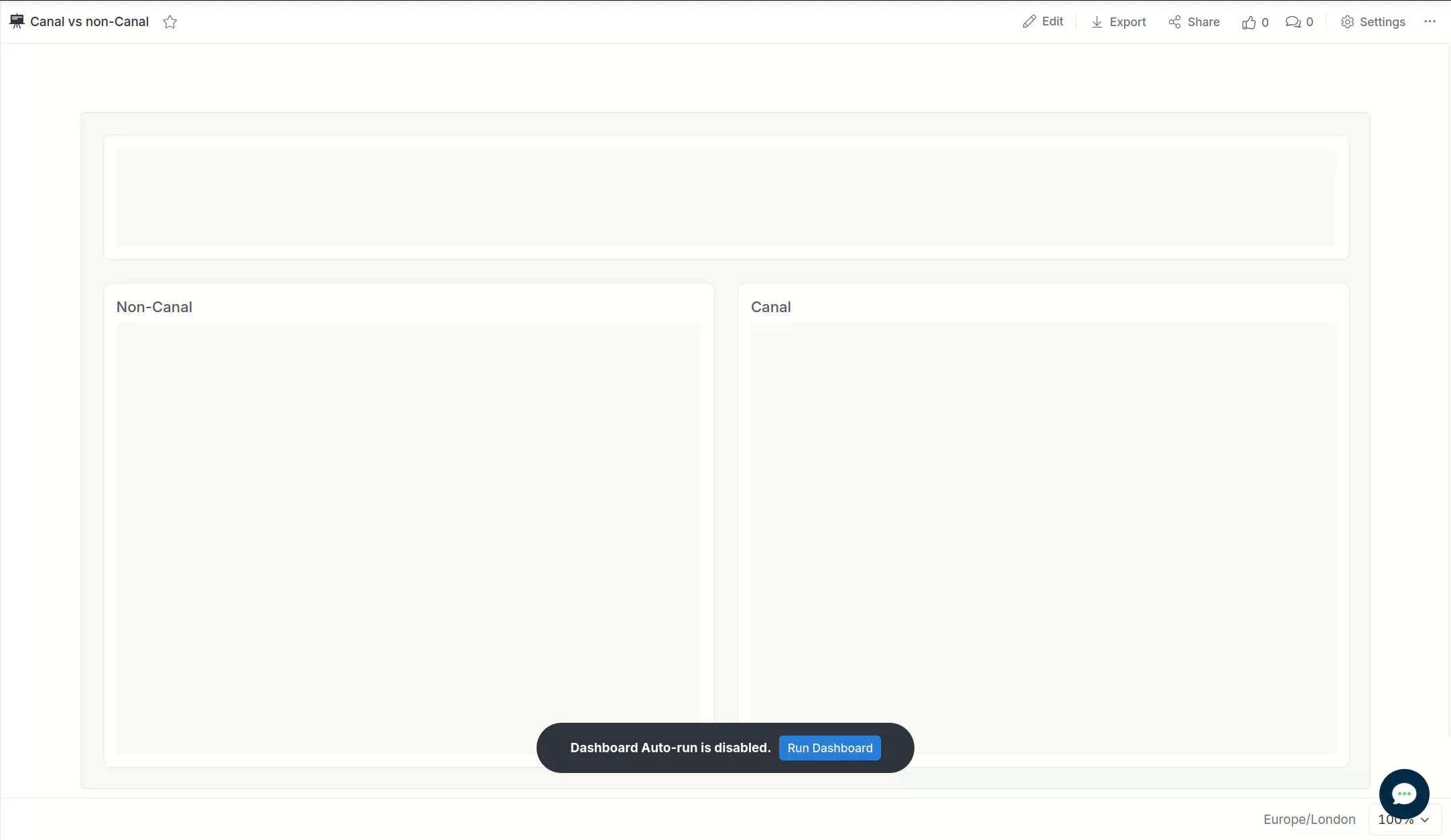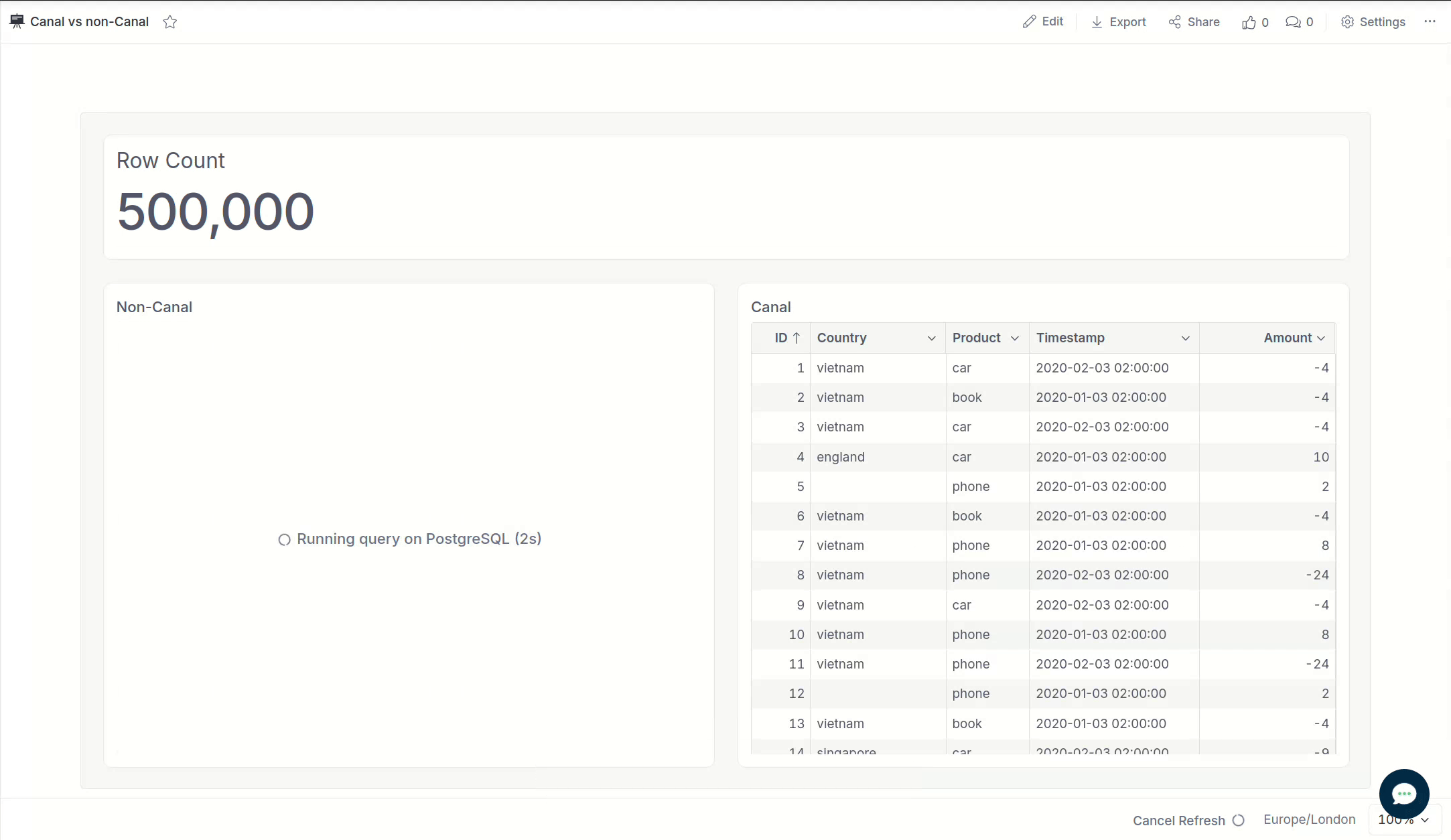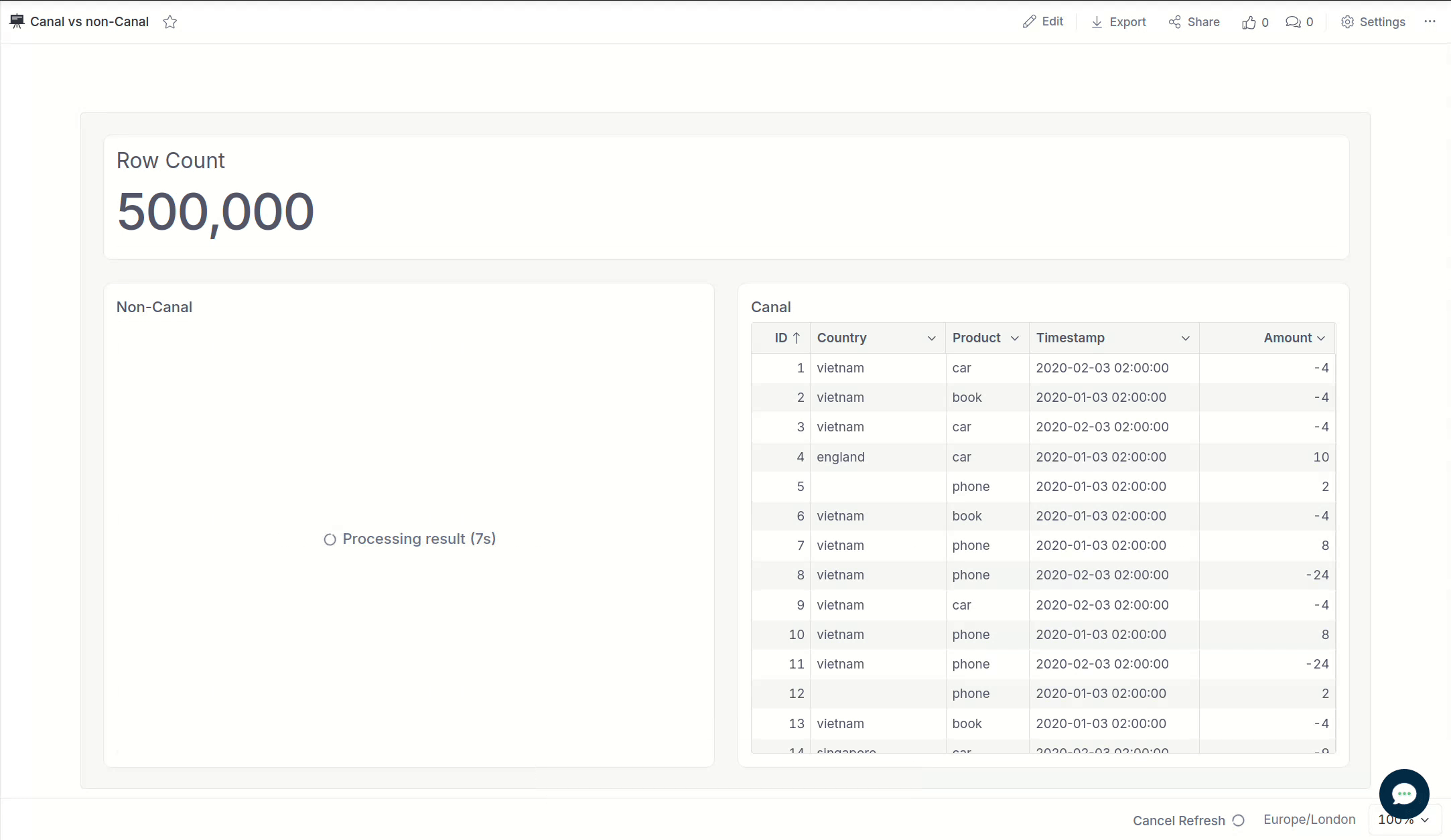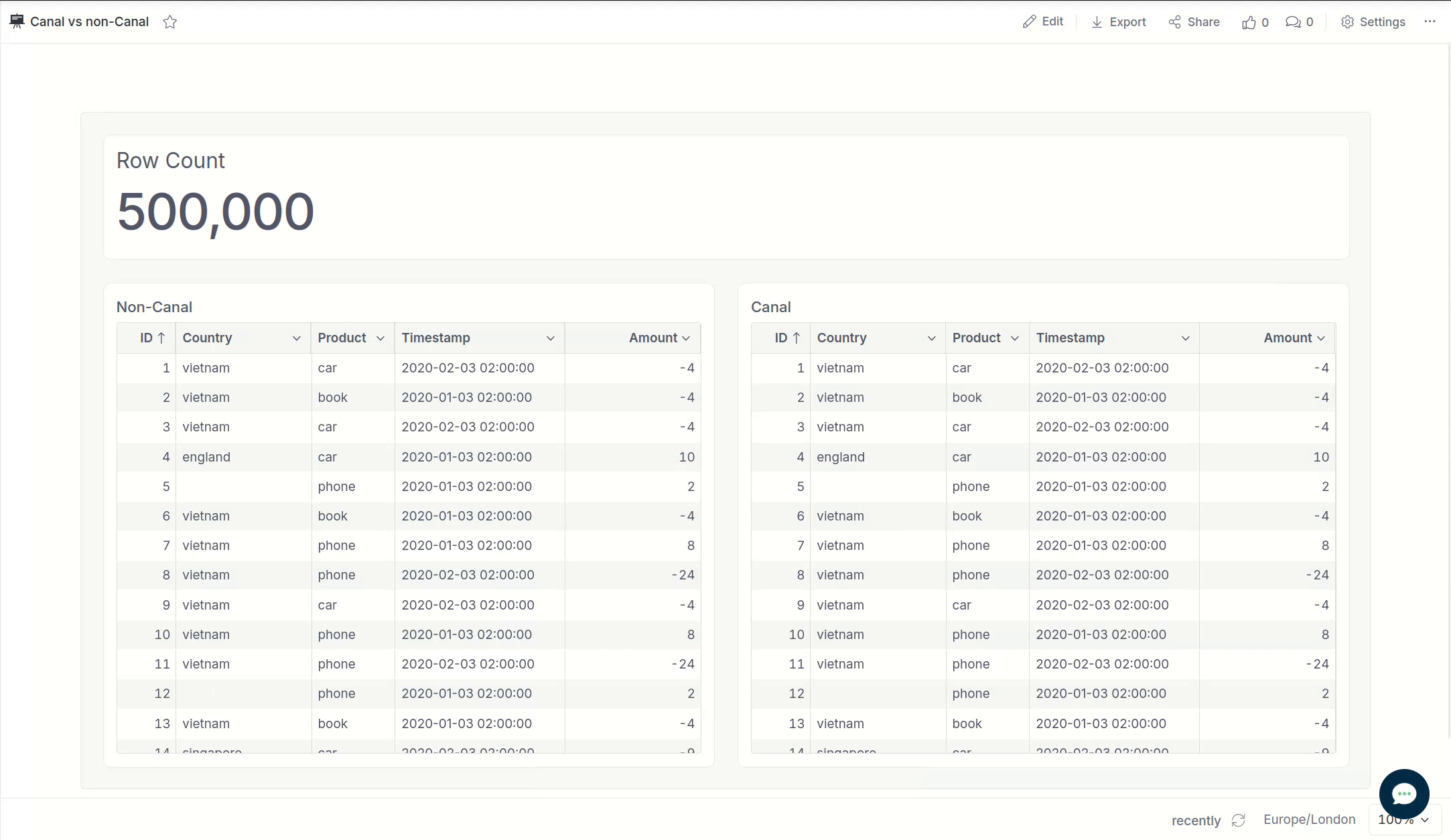
Below is a side-by-side comparison when running a report containing 500,000 rows in the result set.
Holistics Canal will be available soon!
This project is one of our major efforts to continuously bring better performance and experience to Holistics users, and we are really eager to deliver it.
At the point of writing this article, we are very close to releasing Canal with support for the first 2 databases: Postgresql and BigQuery. We also expect to support other databases very soon (Snowflake and Athena are currently at the top of our pending list).
If you are interested, please fill in this form and we will try to notify you with our new updates and Beta release!
p/s Make sure to mention the Database type that you would like Canal to support next. ![]()
Other notes
- While Ruby GIL is typically a challenge to better concurrency and scalability, Ruby itself is still a great programming language that has good performance and lots of features and libraries. Holistics still uses Ruby in a lot of its operations