I’m trying to get my first pre_aggregate setup, but I seem to be missing a step. Here’s the scenario:
- there is a fact table called
warehouse_etl_stack_assignment_examiner_timing - there are dimensions and measures about teams, examiners working various events.
- i’m starting with a simple count stacks (rows in this table represent stacks that have been assigned and completed)
- i made a simple pre_agg to count by several dimensions.
Here’s the dataset block:
pre_aggregates: {
agg_event_stacks: PreAggregate {
dimension completed_at_day {
// It references the field `created_at` in model `transactions`
for: ref('warehouse_etl_stack_assignment_examiner_timing', 'completed')
time_granularity: "day"
}
dimension pa_event {
for: ref('events', 'event_name')
}
dimension pa_calibration {
for: ref('warehouse_etl_stack_assignment_examiner_timing', 'calibration')
}
dimension pa_team {
for: ref('warehouse_etl_stack_assignment_examiner_timing', 'team_name')
}
dimension pa_examiner {
for: ref('warehouse_etl_stack_assignment_examiner_timing', 'examiner_name')
}
measure pa_stacks_count {
for: ref('warehouse_etl_stack_assignment_examiner_timing', 'stack_assignment_id')
aggregation_type: 'count'
}
persistence: FullPersistence {
schema: 'holistics_persistence'
}
}
}
Results
- I manually persisited the pre_aggs
- I opend the SQL browser, and see the pre_agg table w/ correct data included
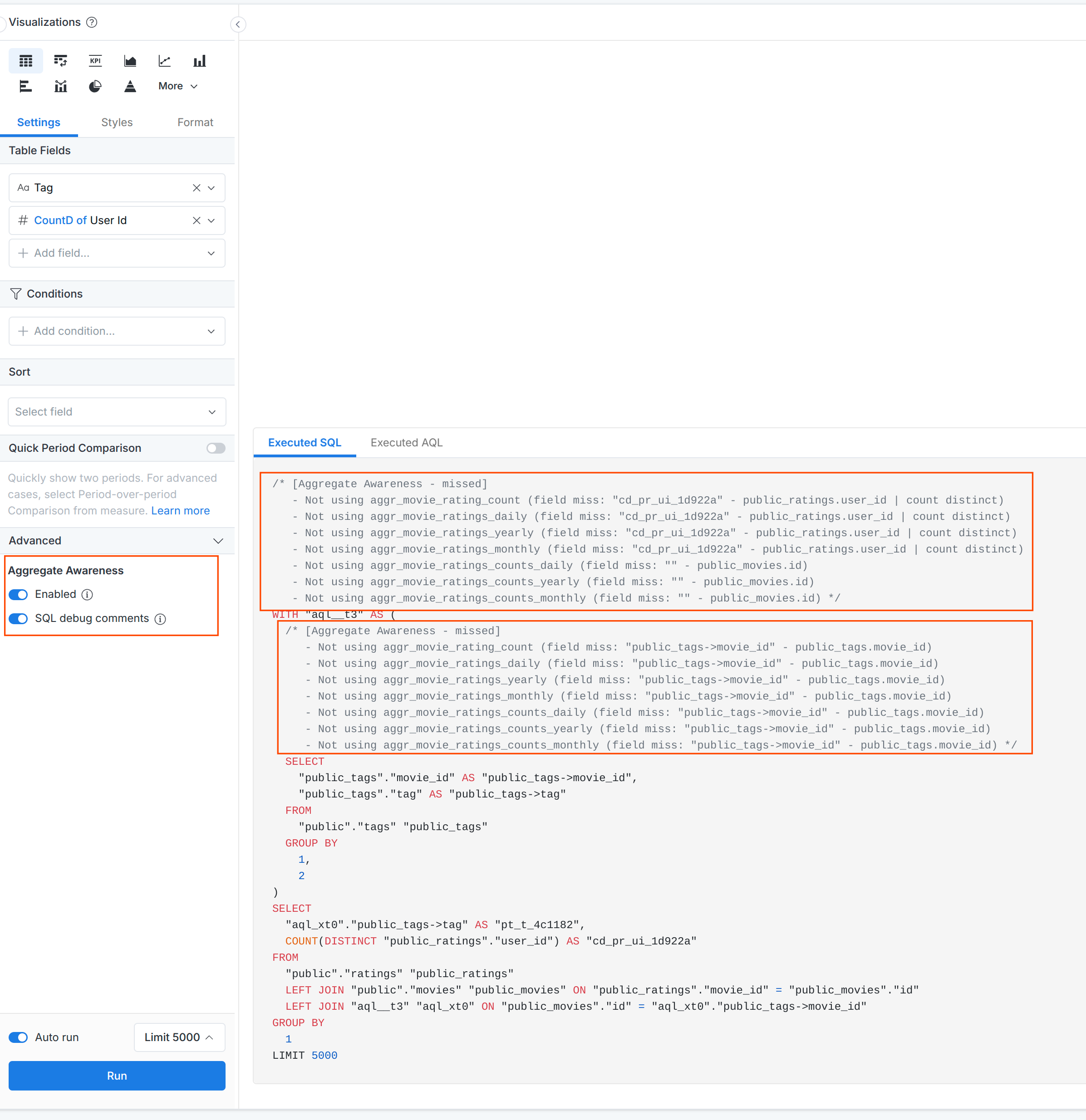
When I go browse the data set, I ran a table with event, calibration, team, examiner, stacks_count (a measure on the fact table) I get this executed SQL (It’s hitting the raw table):
SELECT
"events"."event_name" AS "e_en_615074",
"warehouse_etl_stack_assignment_examiner_timing"."calibration" AS "wesaet_c_234501",
"warehouse_etl_stack_assignment_examiner_timing"."team_name" AS "wesaet_tn_2f4e60",
"warehouse_etl_stack_assignment_examiner_timing"."examiner_name" AS "wesaet_en_73ee56",
COUNT("warehouse_etl_stack_assignment_examiner_timing"."stack_assignment_id") AS "c_wesaet_s_9d2667"
FROM
"xxx"."warehouse_etl_stack_assignment_examiner_timing" "warehouse_etl_stack_assignment_examiner_timing"
LEFT JOIN "holistics_persistence"."events__H4864d3_T1238755" "events" ON "warehouse_etl_stack_assignment_examiner_timing"."exam_event_id" = "events"."exam_event_id"
GROUP BY
1,
2,
3,
4
ORDER BY
5 DESC
LIMIT 10000
NOTE The 'holistics_persistence".events__H4*" is a persisted query model. That is working.
Questions
- are my expectations in line?
- what did i miss?