Hello Holistics power users!
As you may know, we are rolling out a new version of Holistics that takes your analytical game to the next levels. The core components of the new Holistics experience, namely Data Models and Datasets, are constantly evolving, and today we would like to introduce to you a new and more powerful version of our upcoming Dataset!
Drawbacks of the current version
Dataset with root model is not flexible enough
As shared previously, Dataset is a SQL generation interface that produces a series of JOINs according to the fields that you drag in. The current Dataset version requires a root model to act as the first table in the JOIN chain.
While this rigid structure allows Analysts to ensure data to be explored exactly in the way they want, it makes it hard to reuse datasets.
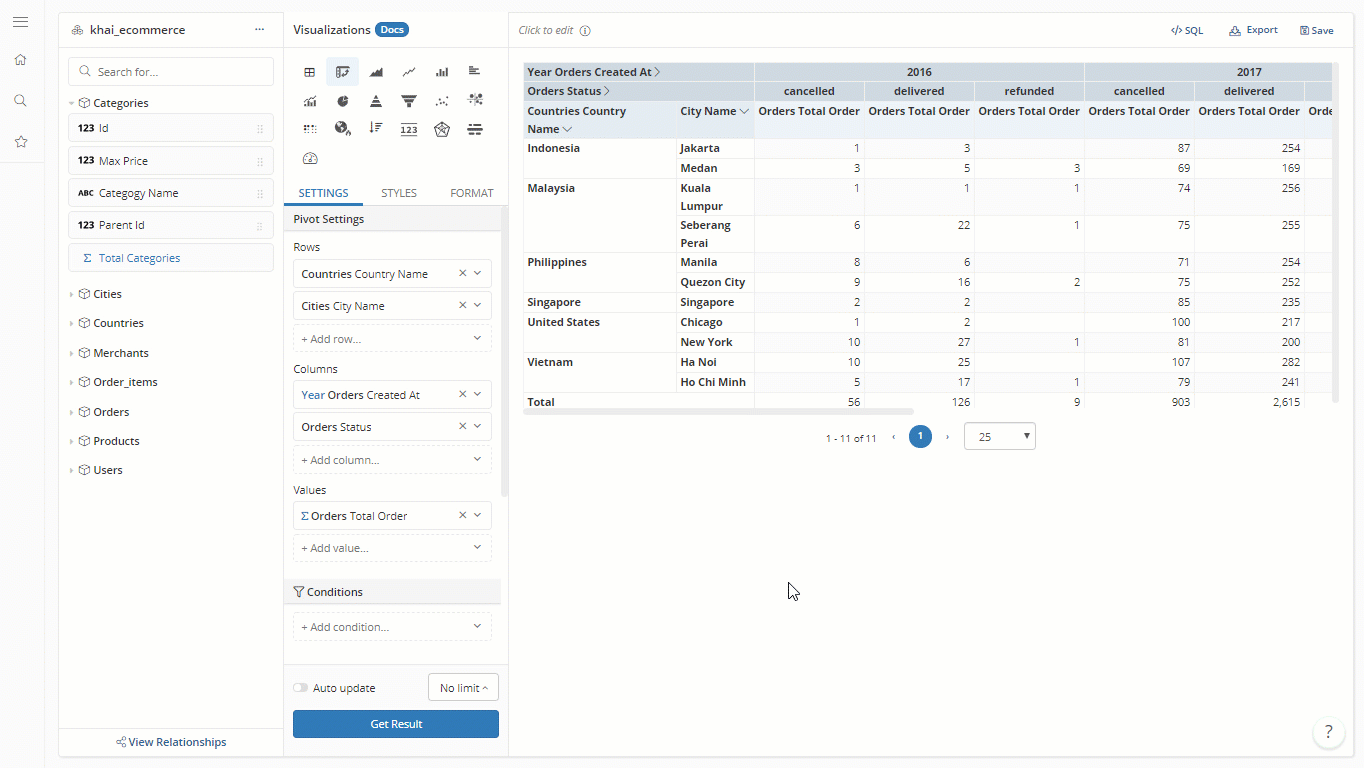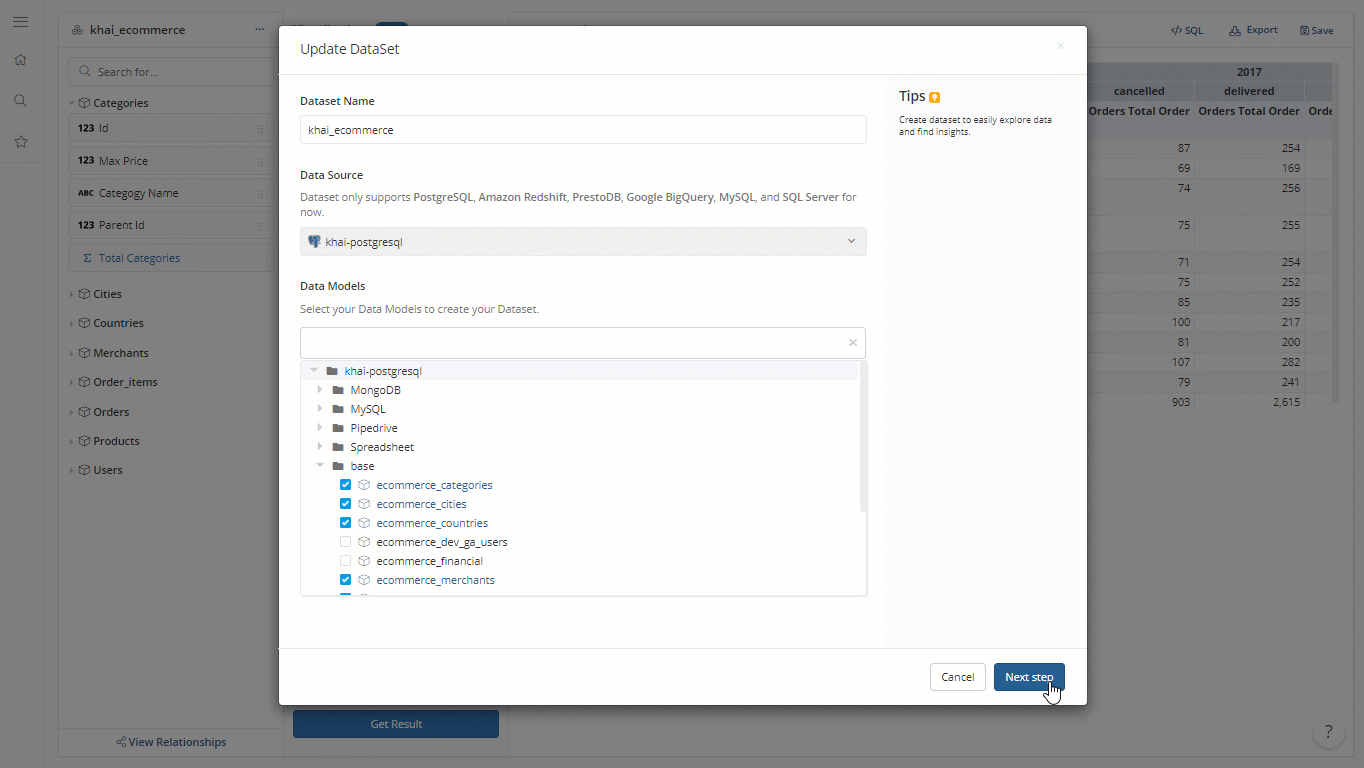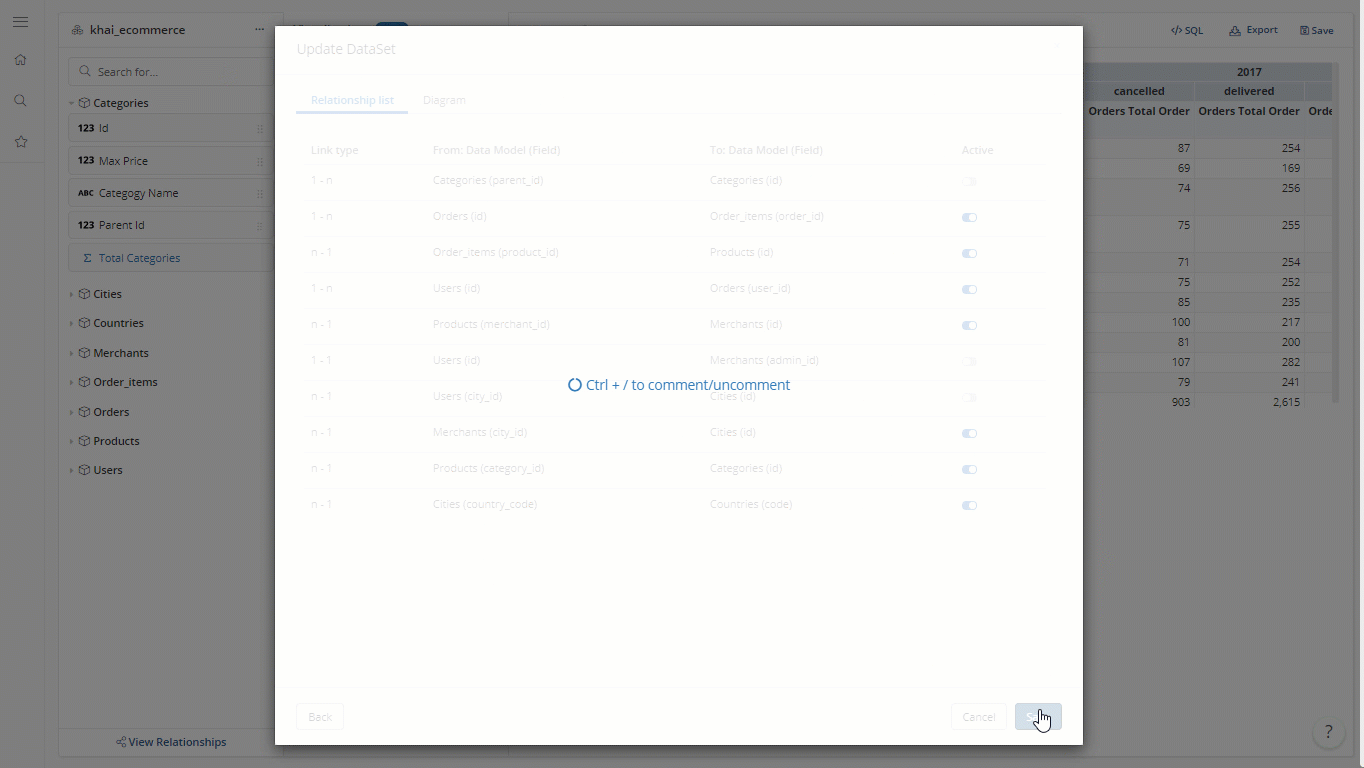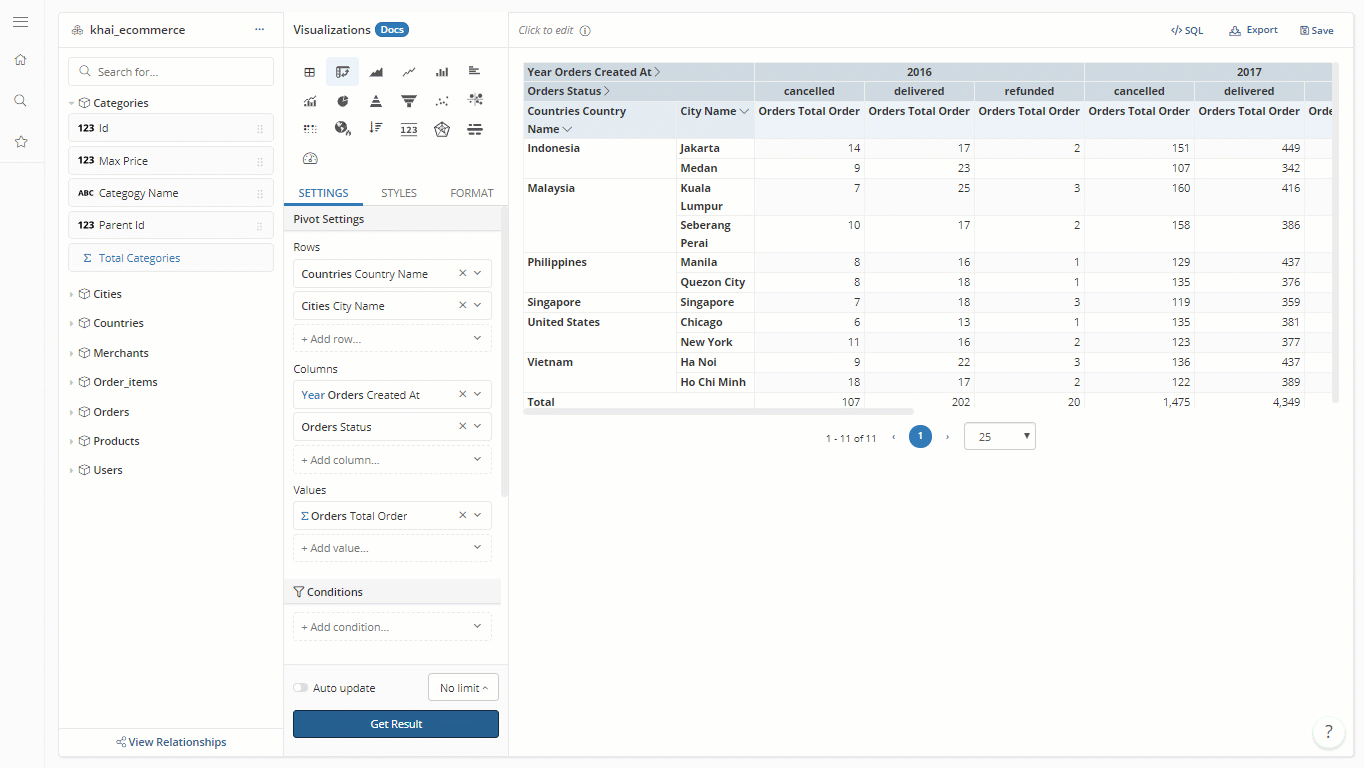
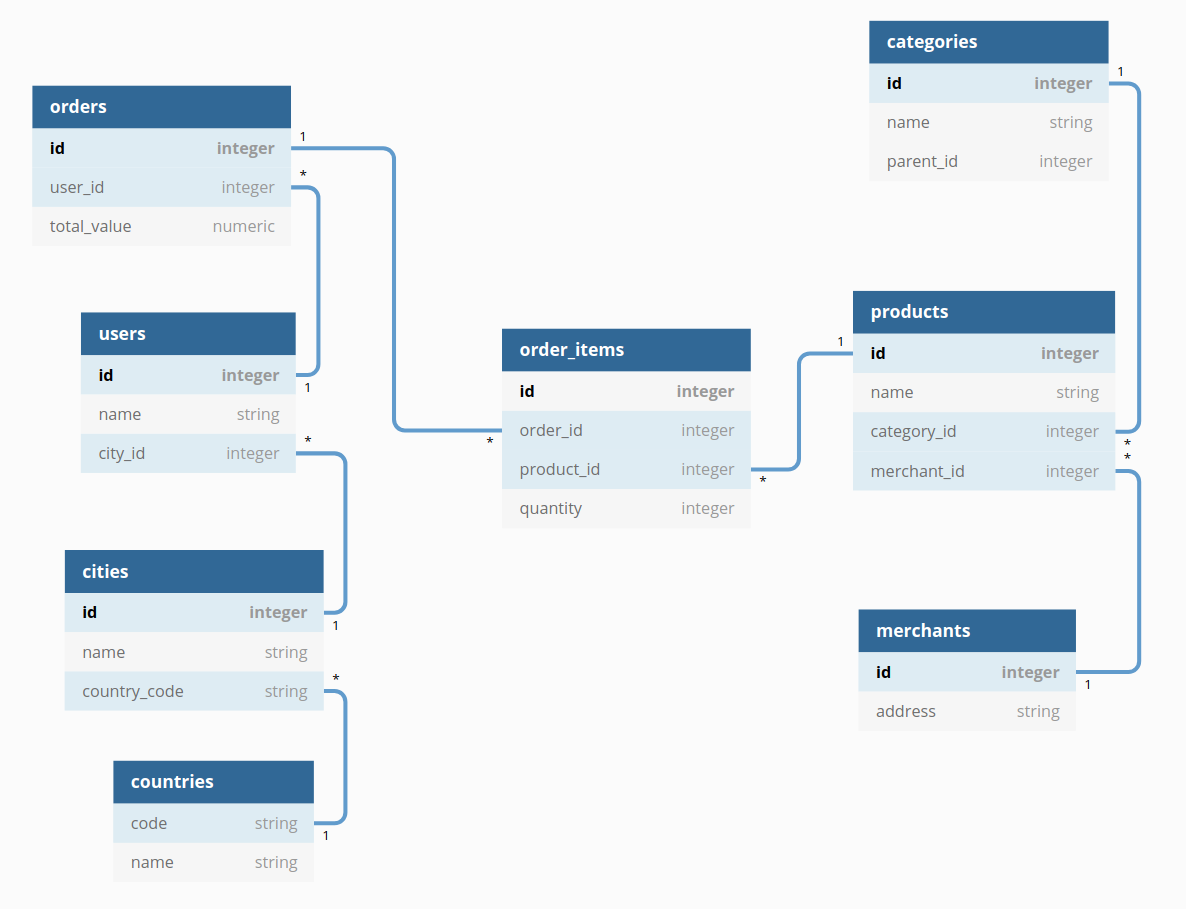
For example, we have models Orders, Users and Countries that have relationships with one another. To explore orders data using supplement information from the other two models, we need to create a dataset called Orders - Full Info with orders as root, while users and countries are peripherals.
This dataset can answer questions like “How many orders are from users at different countries?”. Behind the scene, the generated queries will always have the following JOINs:
SELECT c.country_name, count(distinct o.user_id) as users_count
FROM orders o
LEFT JOIN users u on o.user_id = u.id
LEFT JOIN countries c on u.country_code = c.code
GROUP BY 1
In other words, it produces the list of users who already purchased. If the question is “How many registered users (both purchased and not purchased)?” this dataset will not produce the correct answer. ****
To answer this new question you will need to create a Users Info dataset with users as root:
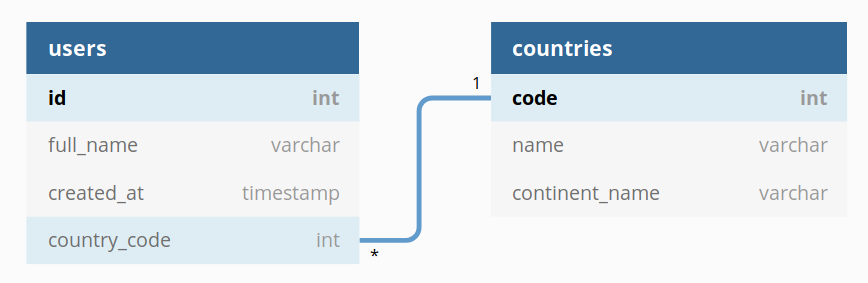
So the JOIN chain will be:
SELECT c.country_name, count(u.id) as users_count
FROM users u
LEFT JOIN countries c on u.country_code = c.code
GROUP BY 1
If there are multiple models that can be linked and explored in different ways, you may need to create multiple slightly different datasets, and it is not an optimal way to reuse data.
Ambiguous path causes confusion
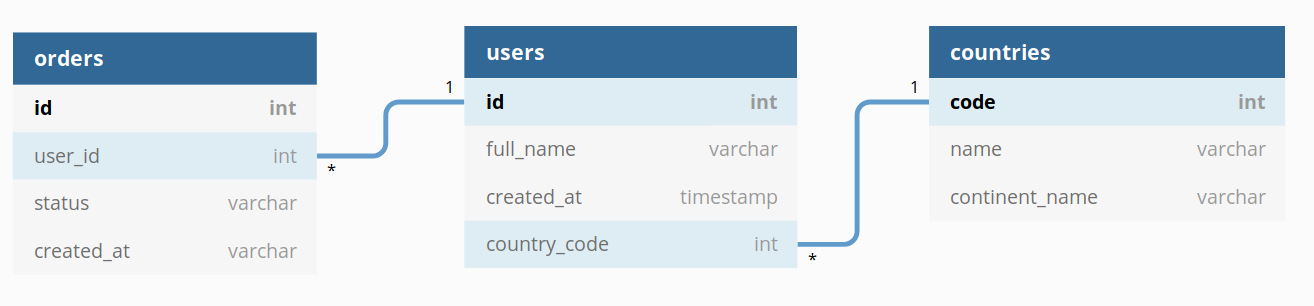
At the current version of Dataset, we allow ambiguous paths between models (Please check our documentation for a detailed explanation). In a Dataset with the models and relationships below, there are multiple ways to go from order_items to cities:
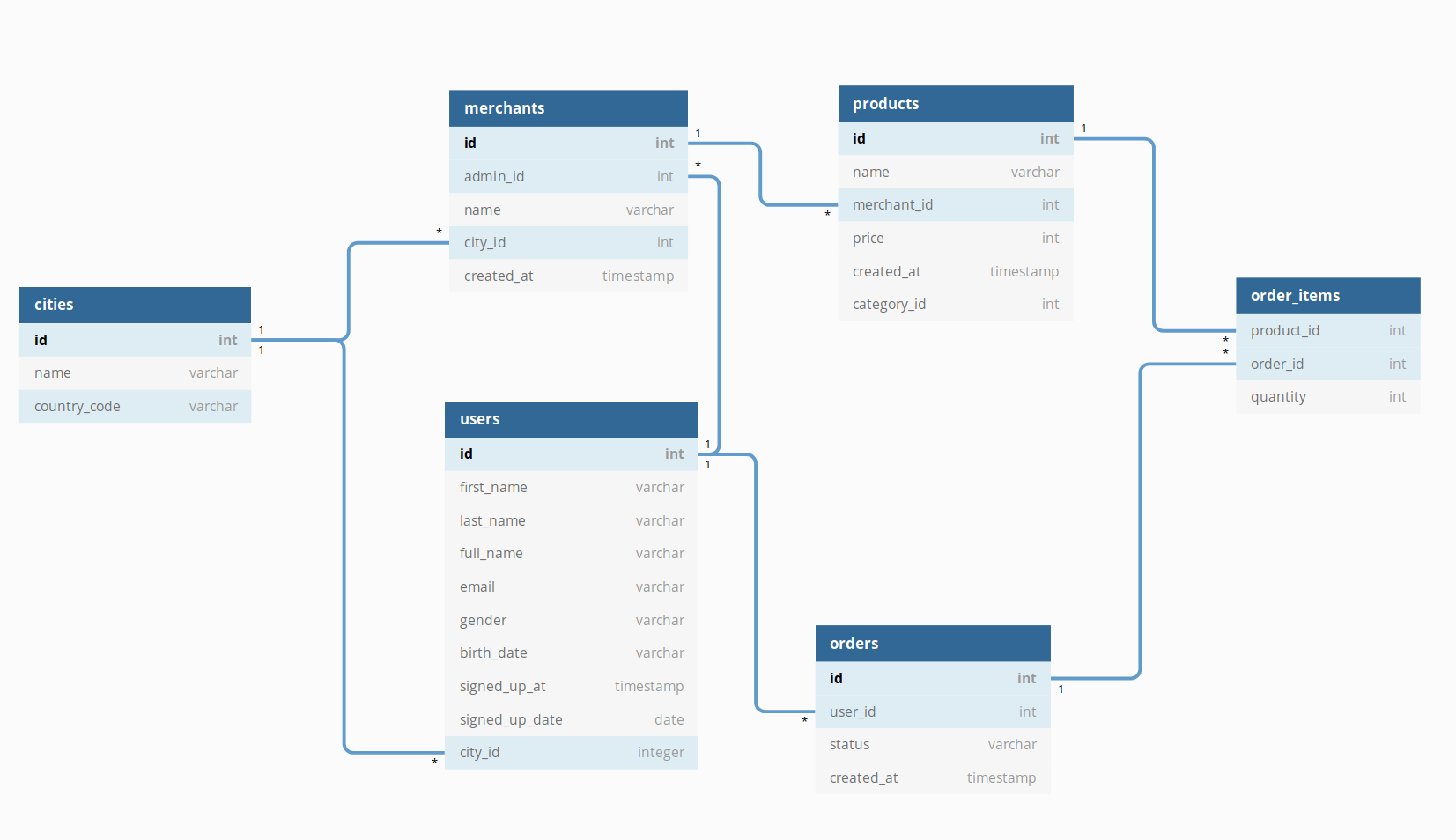

While the concept of JOIN paths is familiar for experienced SQL users, it is not friendly enough for the less technically inclined.
These two drawbacks pushed us to spend more efforts in researching and implementing a new version of Dataset that is easy to use yet powerful at the same time.
Here comes the new Dataset:

No need for root model!
Just as the name suggested, you no longer need to specify a root model when creating a dataset. In other words, you only need one dataset to rule them all!
The same dataset with Orders, Users and Cities can now answer both questions above:
-
How many orders are from users in different countries?".
-
How many registered users (both purchased and not purchased)?

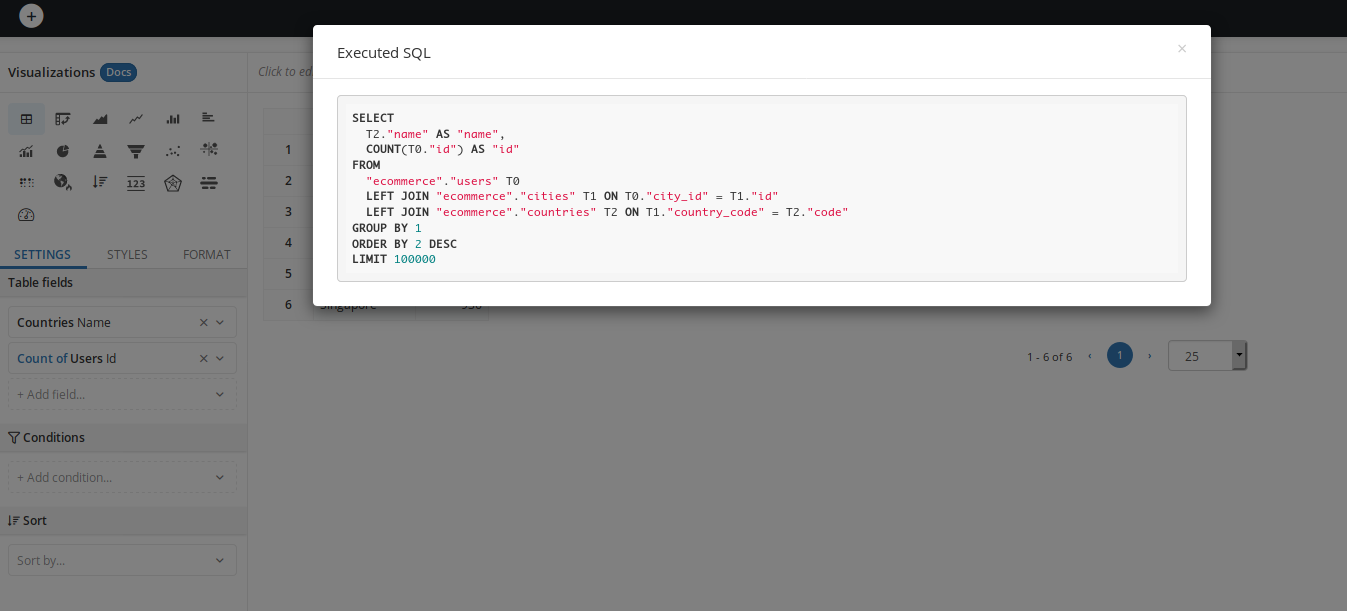
Now you can reuse your Datasets efficiently.
No ambiguous path
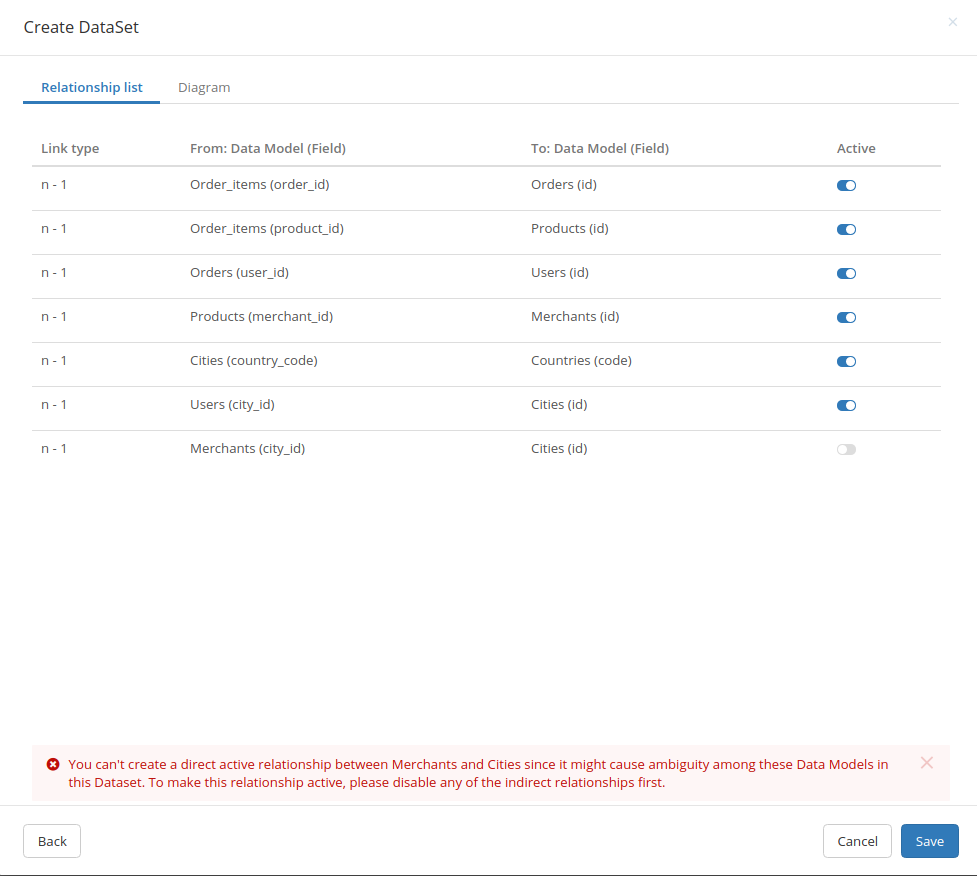
When we detect possible ambiguous paths between models, we will automatically disable a relationship that introduced the ambiguity. For example, if your models have the following setup:
We will disable the relationship between Merchants and Cities models:
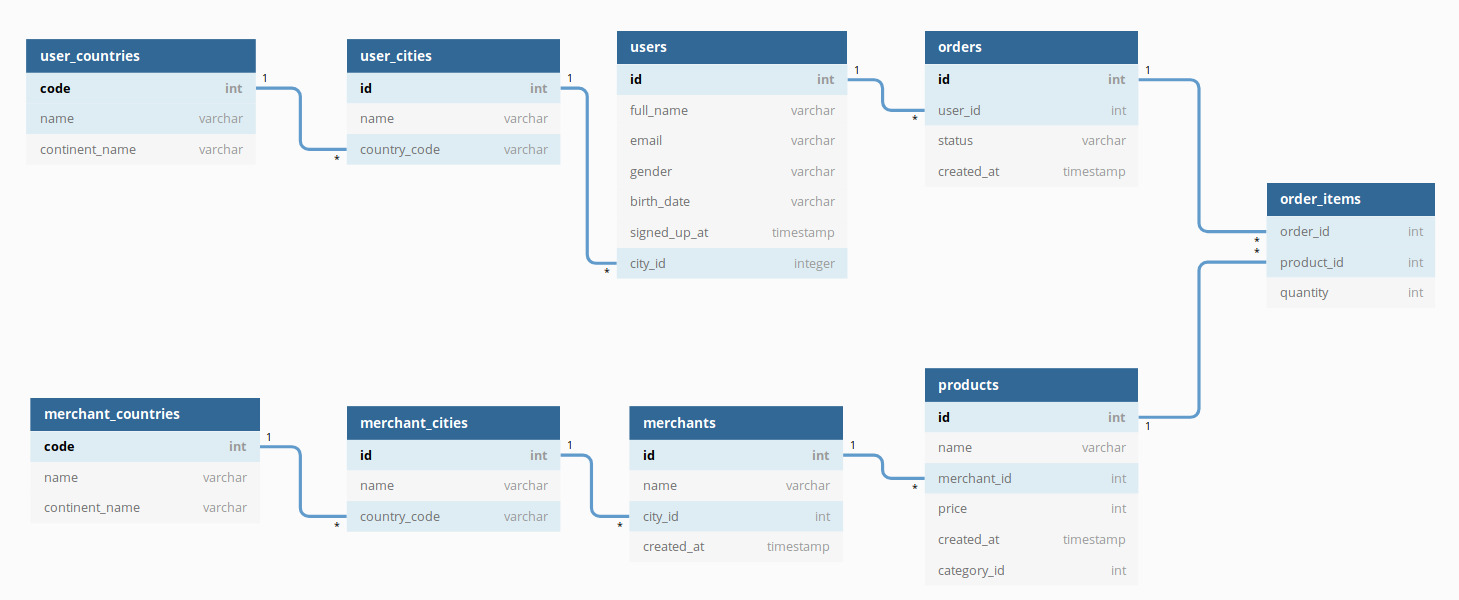
It is recommended that you duplicate Cities and Countries models into dedicated models for Users and Merchants. This makes your dataset clearer to the end-user:
What will happen to my reports and Datasets and how to deal with errors if any?
All of your previous datasets will be automatically migrated to this new version. Your reports, however, may be affected by this change:
- Reports created from Datasets with only one model
will not be affected - Reports created from Datasets with multiple data models but only used fields in Root Model
will not be affected - Reports created from the Dataset but used fields from peripheral models
will be slightly affectedby the migration.
Behind the scene, those fields will be turned into “Legacy Fields” which cannot be edited or used in aggregations. To use the fields, you need to remove them from Viz Settings and drag them in again.
Your reports will still function normally if you do nothing, but we recommend you update your reports with the new fields.
In case you need help while migrating your works, please do not hesitate to contact us at [email protected]. Happy modeling!