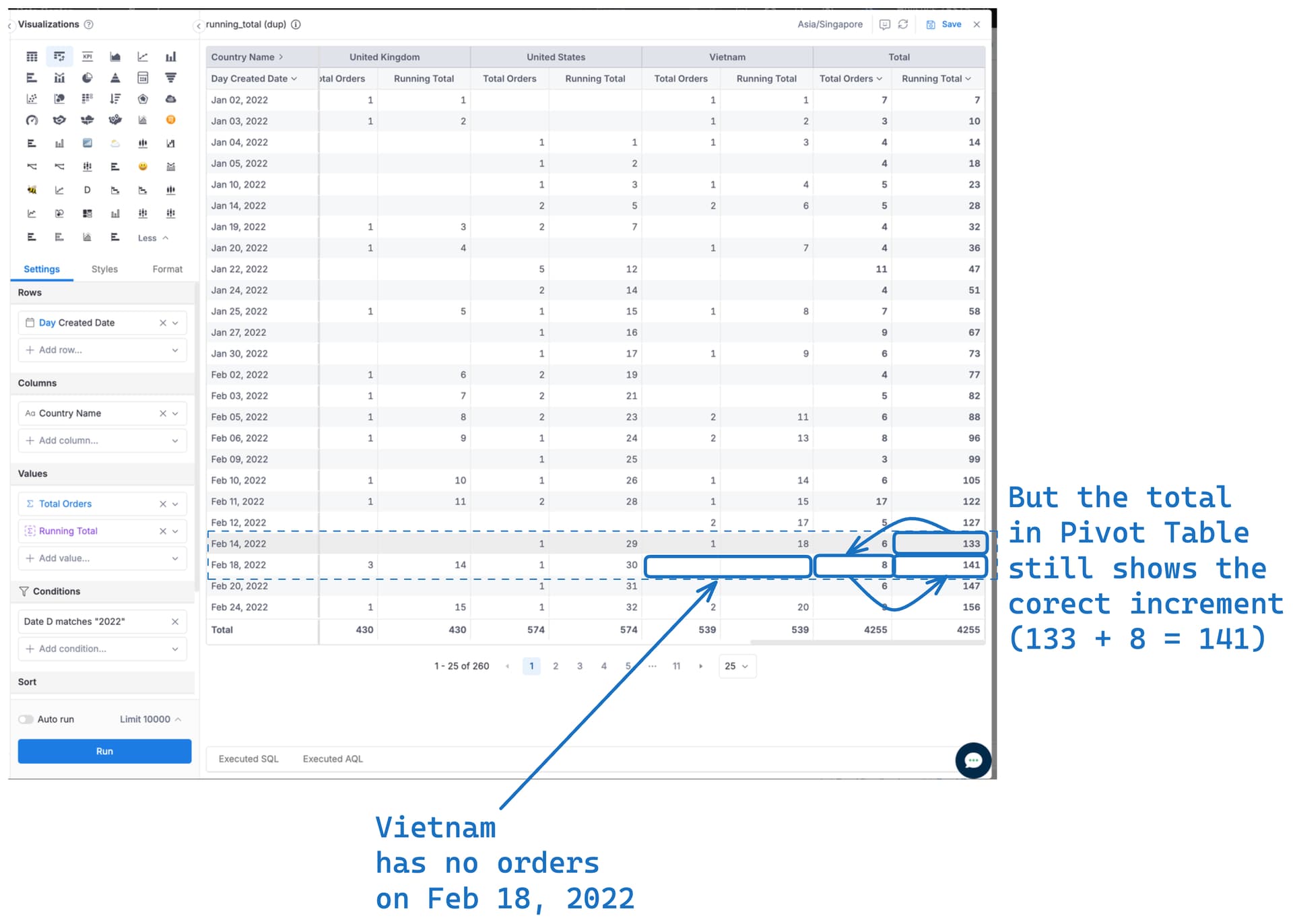
Hi @minhthanh3145 and @Phuong_N_Holistics , apologies for the delay on this! The issue that we’re seeing like Bob mentioned is for visualizations, especially when attempting to stack the values. For example, stacked bar chart.
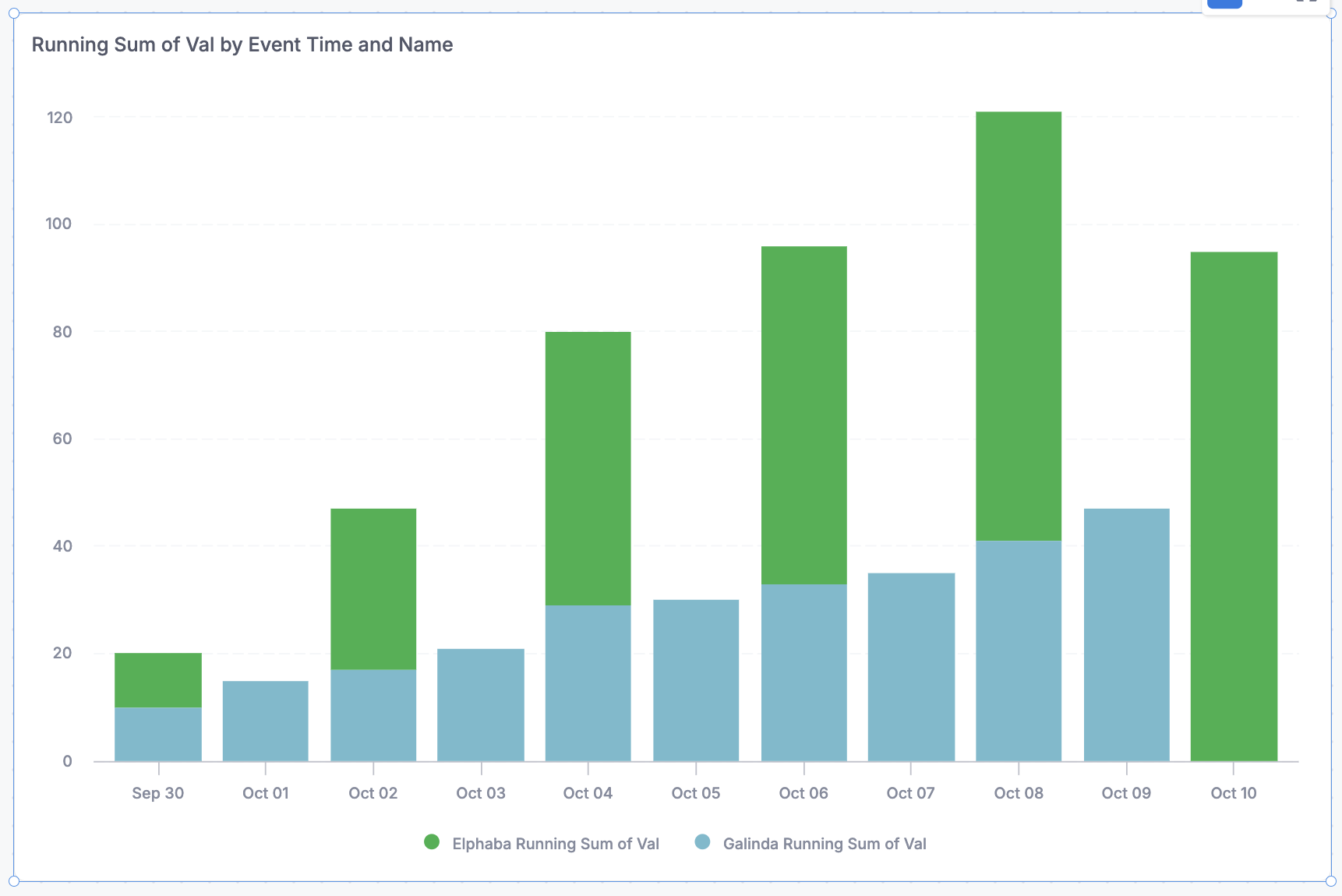
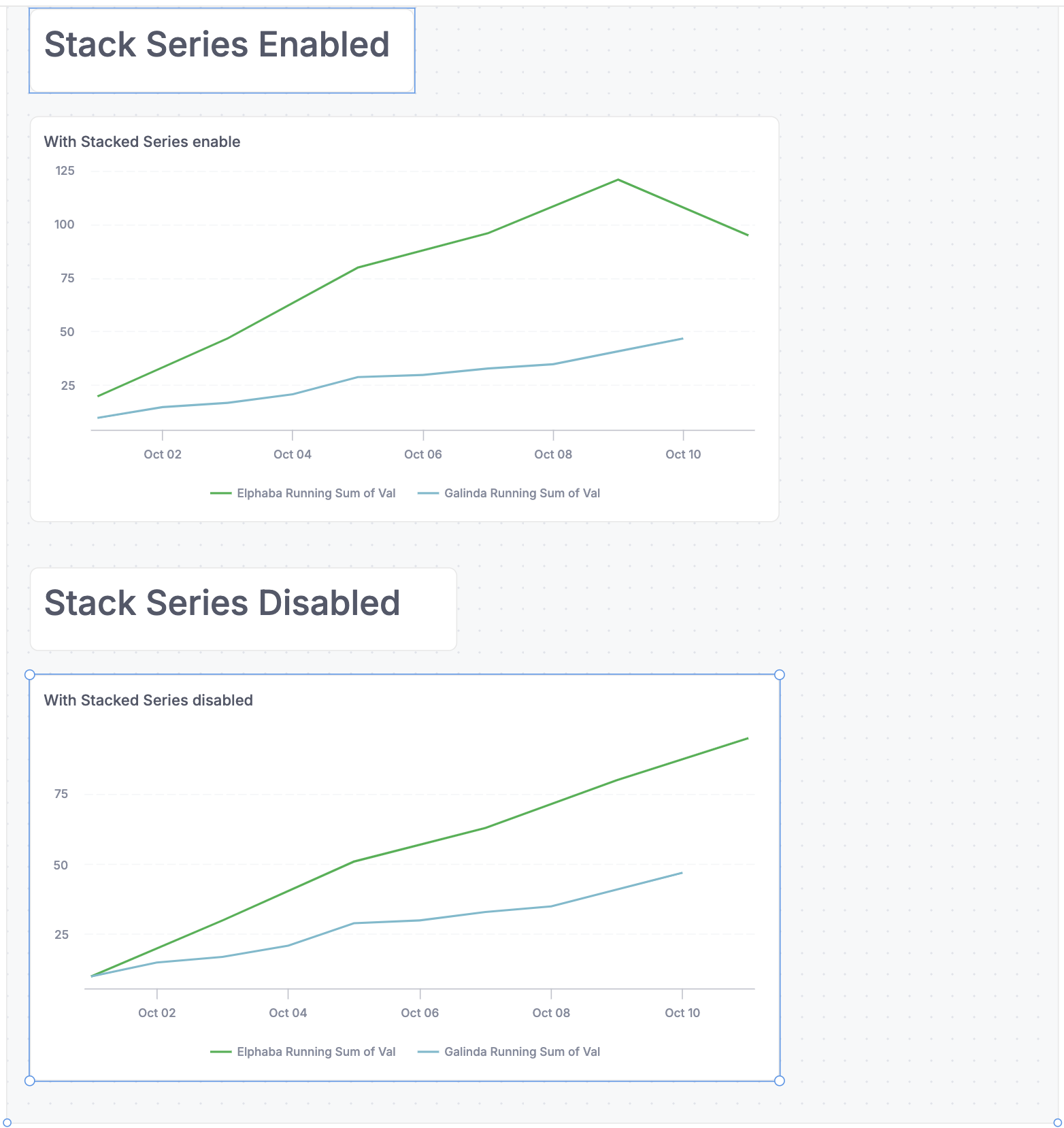
Here’s an example with fake data. Even though blue is individually increasing, and green is individual increasing, on the days that one has no data, it looks like the total is decreasing.
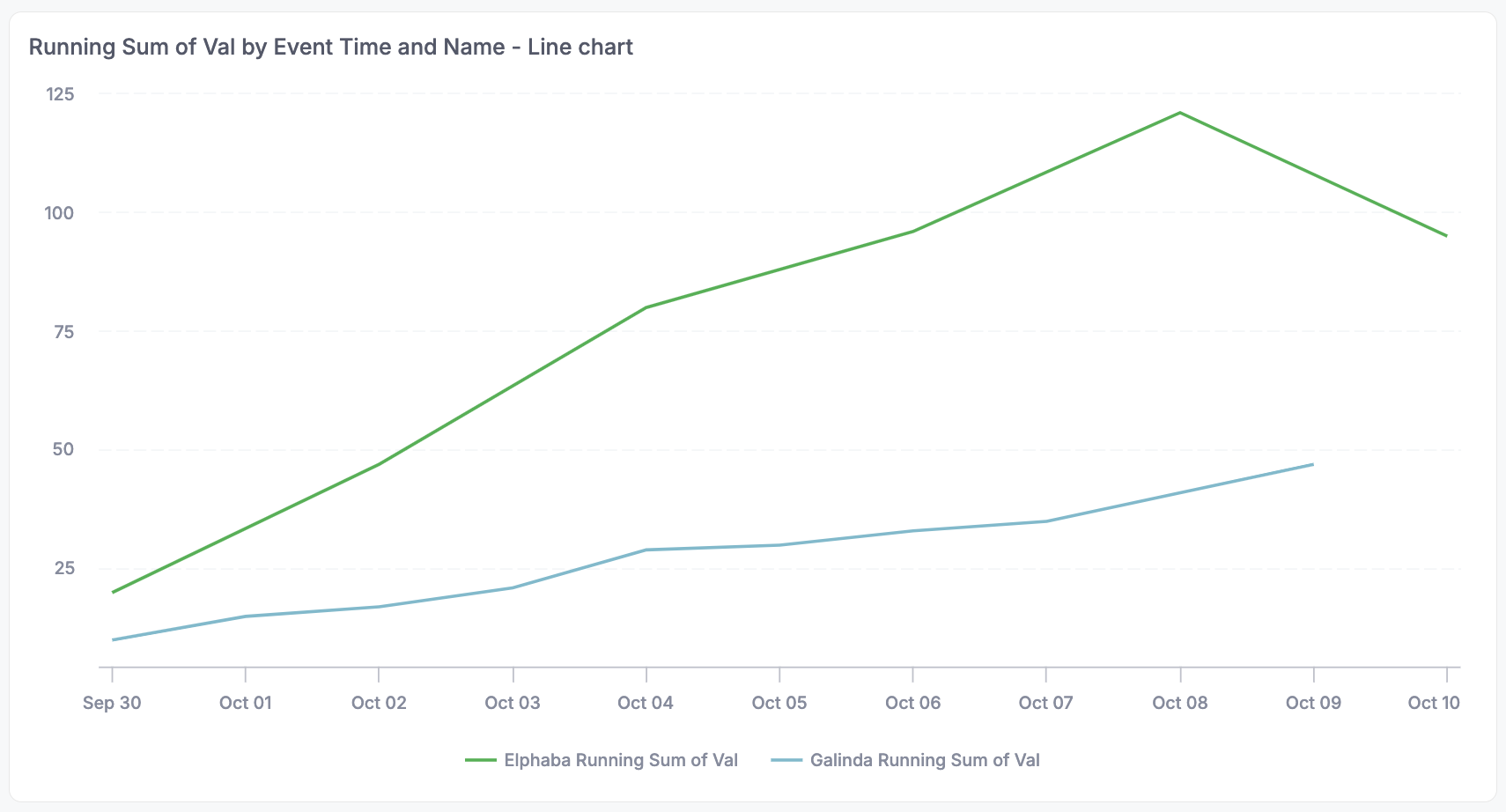
The line chart is a bit better with the stacked approach for most of the time, but looks even weirder at the end when blue has no data - it looks like green has a dip!
I put together a test model, dataset, and dashboard with fake data in case it helps, apologies for the long post (query syntax is BigQuery):
Model testing_running_totals {
type: 'query'
label: 'Testing Running Totals'
description: ''
data_source_name: 'spoileralert'
dimension event_time {
label: 'Event Time'
type: 'datetime'
hidden: false
definition: @sql {{ #SOURCE.event_time }};;
}
dimension name {
label: 'Name'
type: 'text'
hidden: false
definition: @sql {{ #SOURCE.name }};;
}
dimension val {
label: 'Val'
type: 'number'
hidden: false
definition: @sql {{ #SOURCE.val }};;
}
query: @sql
SELECT TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 10 DAY) as event_time, 'Elphaba' as name, 10 as val
UNION ALL
SELECT TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 8 DAY) as event_time, 'Elphaba' as name, 20 as val
UNION ALL
SELECT TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 6 DAY) as event_time, 'Elphaba' as name, 21 as val
UNION ALL
SELECT TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 4 DAY) as event_time, 'Elphaba' as name, 12 as val
UNION ALL
SELECT TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 2 DAY) as event_time, 'Elphaba' as name, 17 as val
UNION ALL
SELECT TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 0 DAY) as event_time, 'Elphaba' as name, 15 as val
UNION ALL
SELECT TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 10 DAY) as event_time, 'Galinda' as name, 10 as val
UNION ALL
SELECT TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 9 DAY) as event_time, 'Galinda' as name, 5 as val
UNION ALL
SELECT TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 8 DAY) as event_time, 'Galinda' as name, 2 as val
UNION ALL
SELECT TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) as event_time, 'Galinda' as name, 4 as val
UNION ALL
SELECT TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 6 DAY) as event_time, 'Galinda' as name, 8 as val
UNION ALL
SELECT TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 5 DAY) as event_time, 'Galinda' as name, 1 as val
UNION ALL
SELECT TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 4 DAY) as event_time, 'Galinda' as name, 3 as val
UNION ALL
SELECT TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 3 DAY) as event_time, 'Galinda' as name, 2 as val
UNION ALL
SELECT TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 2 DAY) as event_time, 'Galinda' as name, 6 as val
UNION ALL
SELECT TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY) as event_time, 'Galinda' as name, 6 as val
;;
models: [
]
}
Dataset test_running_totals_dataset {
label: 'Test Running Totals Dataset'
description: ''
data_source_name: 'spoileralert'
models: [
testing_running_totals
]
relationships: [
]
}
Dashboard test_dashboard {
title: 'test_dashboard'
description: ''''''
view: CanvasLayout {
label: 'View 1'
width: 980
height: 940
grid_size: 20
block v1 {
position: pos(20, 20, 920, 380)
layer: 1
}
block v2 {
position: pos(20, 420, 940, 500)
layer: 1
}
}
theme: H.themes.classic
block v1: VizBlock {
label: 'Running Sum of Val by Event Time and Name - Bar Chart'
viz: ColumnChart {
dataset: test_running_totals_dataset
x_axis: VizFieldFull {
ref: ref('testing_running_totals', 'event_time')
transformation: 'datetrunc day'
format {
type: 'date'
pattern: 'LLL dd'
}
}
legend: VizFieldFull {
ref: ref('testing_running_totals', 'name')
format {
type: 'text'
}
}
y_axis {
settings {
stack_series_by: 'value'
}
series {
field: VizFieldFull {
ref: ref('testing_running_totals', 'val')
aggregation: 'running sum'
format {
type: 'number'
pattern: 'inherited'
}
}
settings {
point {
value: 'Elphaba'
color: '#2AB24AFF'
}
point {
value: 'Galinda'
color: '#70BBCDFF'
}
}
}
}
settings {
row_limit: 5000
}
}
}
block v2: VizBlock {
label: 'Running Sum of Val by Event Time and Name - Line chart'
viz: LineChart {
dataset: test_running_totals_dataset
x_axis: VizFieldFull {
ref: ref('testing_running_totals', 'event_time')
transformation: 'datetrunc day'
format {
type: 'date'
pattern: 'LLL dd'
}
}
legend: VizFieldFull {
ref: ref('testing_running_totals', 'name')
format {
type: 'text'
}
}
y_axis {
settings {
stack_series_by: 'value'
}
series {
field: VizFieldFull {
ref: ref('testing_running_totals', 'val')
aggregation: 'running sum'
format {
type: 'number'
pattern: 'inherited'
}
}
settings {
point {
value: 'Elphaba'
color: '#2AB24AFF'
}
point {
value: 'Galinda'
color: '#70BBCDFF'
}
}
}
}
settings {
row_limit: 5000
}
}
}
}