Hi Matt,
Is this correctly describe your use case?
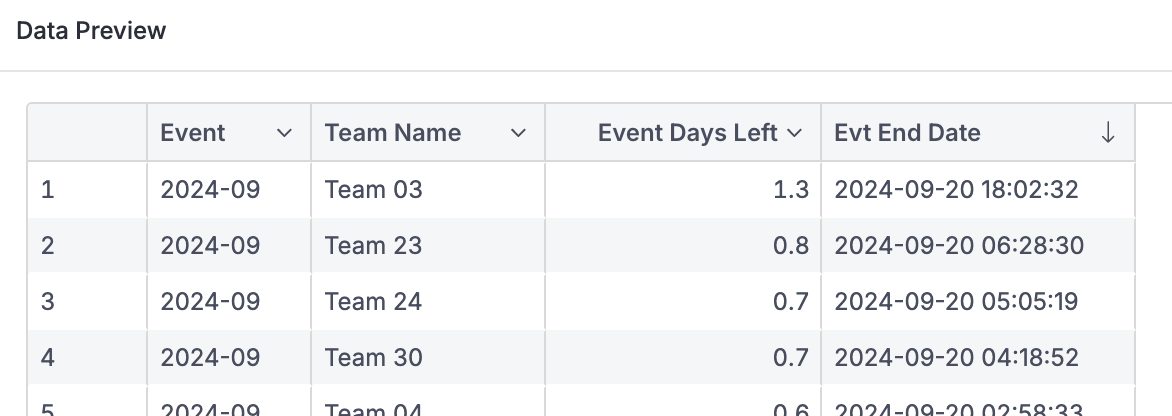
From your description, it sounds like you have an event with multiple teams, each team having its own assignments and respective expected end dates. Initially, you’re seeing the correct maximum expected end date for each team within each event, like this:
| Event Name |
Team Name |
Max Expected End Date |
| Event 1 |
Team 1 |
2024-09-01 |
| Event 1 |
Team 2 |
2024-09-02 |
| Event 1 |
Team 3 |
2024-09-03 |
| Event 2 |
Team 1 |
2024-09-01 |
| Event 2 |
Team 2 |
2024-09-02 |
| Event 2 |
Team 3 |
2024-09-03 |
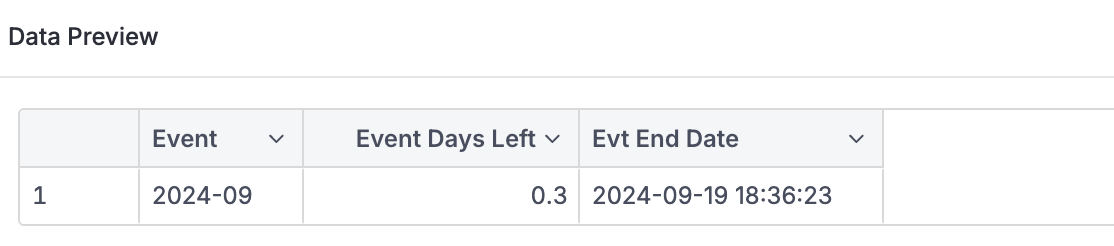
However, when you remove the team dimension to view the overall maximum expected end date for each event, instead of the expected result:
| Event Name |
Max Expected End Date |
| Event 1 |
2024-09-03 |
| Event 2 |
2024-09-03 |
You’re seeing an average of the underlying data.
Could you clarify what you mean by “average”? Since we’re dealing with dates, it’s not clear how averaging them is being calculated in your exploration.
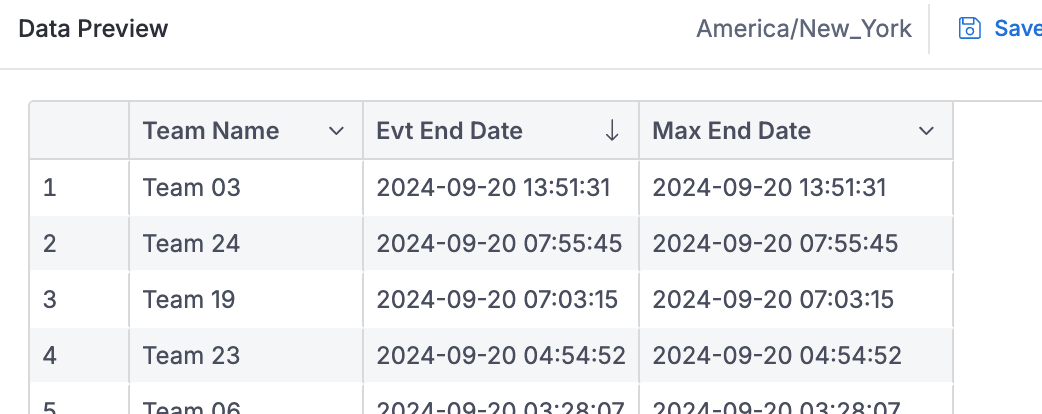
In general, since max() is an additive metric, the expected result when you remove the team dimension should still show the maximum end date across all teams for each event. If that’s not happening, there might be a configuration issue.
To help troubleshoot, could you provide additional screenshots or sample data, along with the configuration of your current exploration? This will help me better understand the structure and provide more targeted guidance.
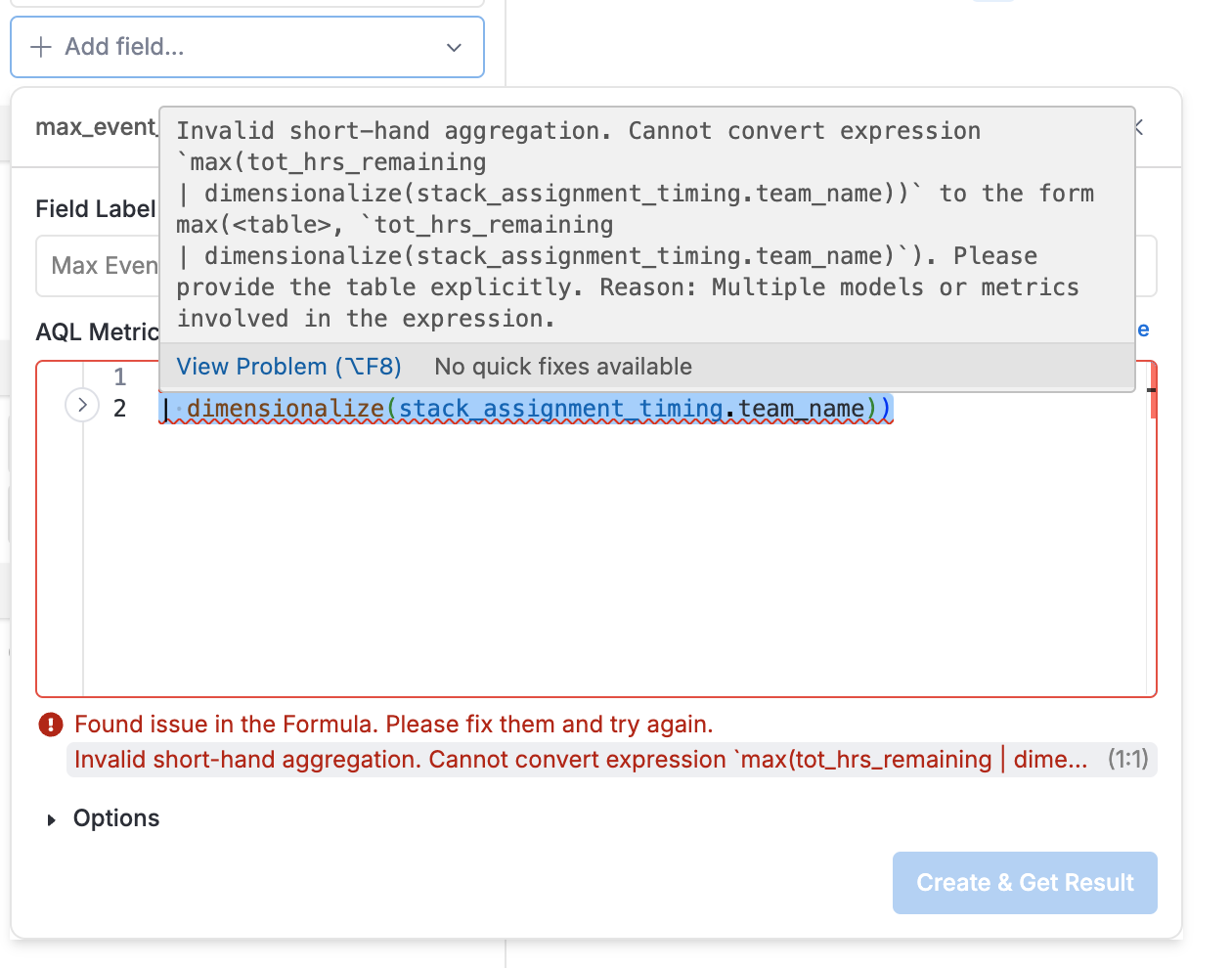
As for the AQL formula you’re working with, the issue may lie in how you’re using group without the table parameter. Assuming tot_end_date is a metric, you could try the following:
stack_assignment_timing
| group(events.event_name, stack_assignment_timing.team_name)
| max(tot_end_date)
If tot_end_date is a dimension, you’ll need to wrap it with max() like this:
stack_assignment_timing
| group(events.event_name, stack_assignment_timing.team_name)
| max(max(stack_assignment_timing.tot_end_date))
which is equivalent to
max(
stack_assignment_timing
| group(events.event_name, stack_assignment_timing.team_name)
| select(max(stack_assignment_timing.tot_end_date))
)
Let me know if this helps or if you’d like to dive deeper into any specific areas.