Question for @Abdel, @Alex_H et @DataGeekDude who contributed to this feature request : how do you solve this issue right now ? I don’t see a viable option and I don’t want to manually change all the schema and datasource names when deploying to production ![]()
At the moment I do not have a solution to this
Hello,
We use holistics 4.0 and started migrating to AML 2.0.
We were facing the same kind of issue.
One way to do it (hacky solution ![]() ) is to create a model for example
) is to create a model for example env.aml with the following code:
Model env {
type: 'table'
label: ''
description: ''
data_source_name: 'MY_DATASOURCE_TO_USE'
table_name: 'MY_SCHEMA_PREFIX'
}
Then, all models can refer to the env model for defining the default datasource to use. Here is an example:
use env
Model my_model {
type: 'table'
label: 'My model'
description: ''
data_source_name: env.data_source_name
dimension field_1 {
label: 'Field 1'
type: 'number'
hidden: false
definition: @sql {{ #SOURCE.MY_FIELD_ID }};;
}
owner: '[email protected]'
table_name: '"' + env.table_name + '_SCHEMA"."MY_TABLE"'
}
Datasets can force models to use a specific data_source_name :
use env {
env_dev
}
use models {
my_model
}
Dataset my_dataset {
label: 'My dataset
description: ''
data_source_name: env_dev.data_source_name
models: [
my_model
]
relationships: [
]
owner: '[email protected]'
}
Now, to make the data_source_name overriding working correctly, we will have to avoid using schema prefix because it can’t be overrided at the dataset layer as the data_source_name.
2 Likes
I would like to open this subject again : like @Abdel it would really help us to have a staging env distinct from production.
We use an external git to version our models but we find that :
- the dataset preview feature is not enough to validate a dataset (you need to start building dashboards to do that
- it’s very difficult to deal with test vs production database/schemas within one single holistics env
If we could have a “Prod” holistics env connected to the master branch of our git repo and our prod datawarehouse as well as a “Test” Holistics env connected to a staging branch of the same repo and a staging datawarehouse it would very much simplify all these issues.
And I think Holistics already has all the features to support this : you only need external git support ![]()
Hi @dacou , thanks for sharing this. Could you specify what kind of outcome you’re seeking from Dataset Validation? Does the Preview Option work in this case?
Hi @Khai_To , what I mean is that in order to fully validate a dataset, we need to start building reports, dashboards and filters to confirm that it is a good fit for the intended purpose.
For now, the models and dataset preview feature are useful for the first controls :
- “model preview” : detect formatting issues, visual check of measures
- “dataset preview” : control relationship + sandbox for dataset first checks
When these first checks are done, we publish the dataset in order to start building dashboard, reports and filters. At this stage, the dataset is already merged in the master branch but some major changes can still occur on to implement features that could not be detected before :
- custom dimensions (groupings, encodings, value ranges, …)
- custom models (depending on the visuals that we are trying to build
- data formatting
- pre-aggregation (depending on query performance feedback)
- …
For a new dataset, these first steps happen with models and datasets querying a staging database.
When it’s done, we publish the new tables to our production database and switch the datasource of our models and datasets to production.
With this workflow it is not easy to have at the same time multiple versions of the same models and datasets (one production version and one+ version for dev/test).
If we had a “prod” vs “test” holistics env, we would solve these issues :
- maintain both test/prod versions of models and dataset
- expose new versions of datasets to some key users for validation/iteration on the “test” env
- and only when all of this is done, merge to master and publish to “prod” Holistics
The main issue with this is that dashboards built on the “test” env would have to be rebuilt from scratch when moving to the “prod” env.
One ideal solution would be to have one single holistics env but have “branch support” included in the URL for both reporting and modeling ![]() so that we can share with our key users a dataset or dashboard for review before merging to master :
so that we can share with our key users a dataset or dashboard for review before merging to master :
https://eu.holistics.io/{release-xxx}/dashboards/v3/…
1 Like
Hi @dacou,
Thanks for your detailed explanation. ![]()
I totally understand that our current version doesn’t support this use case well.
The only (upcoming) option that you can use is our Preview Reporting, but we haven’t released it yet due to several performance issues. Our team is actively working on the improvement so that we can release it as soon as possible.
I think that this use case is totally valid. We’re discussing internally how to best solve this, and one of the options we’re thinking of is environment variable where we allow users to customize the behavior of your project depending on where the project is running (either Production, Development, or a specific Branch).
For example, you can define the dataset
Func ds_name () {
if (env.IS_PRODUCTION == true) {
env.PROD_DB_NAME
} else {
env.DEV_DB_NAME
}
}
Dataset name {
label: 'Name'
description: 'Something here'
data_source_name: ds_name()
// Other configurations
}
and the .env file
IS_PRODUCTION=true
PROD_DB_NAME=prod_db_name
DEV_DB_NAME=dev_db_name
Do note that it’s just the drafted solution ![]() . The final one could be different.
. The final one could be different.
With this use case, basically, you want to share a version of your Data (dashboard) to another Data Analyst so that he/she can check review it before Deploying to Production.
With the release of our upcoming Preview Reporting, you can basically Commit and Push your changes to a particular branch and ask the reviewers to checkout that branch and go to the Dashboard to validate the data.
But of course, with the branch name included in the URL, it would be much easier for you to quickly share the Dashboard with the reviewers.
I will note this down and consider supporting it in the future.
Do let me know if you have any questions.
Thanks,
Hi,
The environment variable feature is a great addition. We use a hacky workaround for now to simulate this (detailed by @Julien_OLLIVIER in this post ).
Regarding the “Preview reporting” feature :
- Will we be able to save reports and dashboards across “preview reporting” sessions ? This would be a must have to collaborate between data analysts and end users when dataset reviews last multiple days.
- Will it be available to users other than data analysts ? Most of our “dataset reviewers” are product owners and business users who don’t have access to the modeling view right now.
Damien
1 Like
Our upcoming release for Preview Reporting won’t allow you to save any changes to the Reports/Dashboards (in the Preview Session).
Also, the Preview Reporting is user-based meaning that other users won’t observe the same Reporting Behavior as you do.
It will refer to your current Working Directory (instead of the commit) to reflect changes to the Reports/Dashboards. Thus, if you make changes in the Reporting while in Preview session (for e.g., replace or remove a field in a report), other users (viewing reporting items) will be affected.
However, could you share why do you need to save reports and dashboards while in Preview Session?
The option Preview Reporting is only available for users who have access to the Modeling layer. It’s currently not designed for non-DA users to do Acceptance Testing.
However, if you use case is to allow non-DA users to check and validate the Dashboard before Production Deployment, we would need to consider another approach.
HI @Khai_To
How about serialization approach? Where you’re able to export all or specific parts of the Holistics contents and load it into another instance (dev instance).
That gives you much more possibilities
Hi @Abdel, could you please share a specific example for that workflow?
+1 on this feature. We use dbt dev schemas for prototyping modeling changes
1 Like
How far are we on this topic?
We are very interested in creating a staging environment that we can connect to our local schemas.
E.g. after a dbt run on my local schema, it would be nice if i could see the changes and build dashboards on that data straight away.
Currently we have to merge into master before being able build reports, which slows down the process significantly.
1 Like
Hi @Spanggaard1994,
This feature is not supported yet but this has already been added to our roadmap this year. Our team is doing product research and we will let you know when there is an update on our side.
For more information, you can refer to our doc here Dynamic Development/Production environment | Holistics Docs (4.0)
Note: the doc above is just our early design for the Development Workflow testing, so the final design could be a bit different
Hi @Abdel,
We’re now working on this feature Dynamic Development/Production environment. Although the design is subject to change, our direction is to assign one environment per branch and automatically use that environment when running the project.
Let me know if this can solve your use case
@HuyVu yes. That makes complete sense.
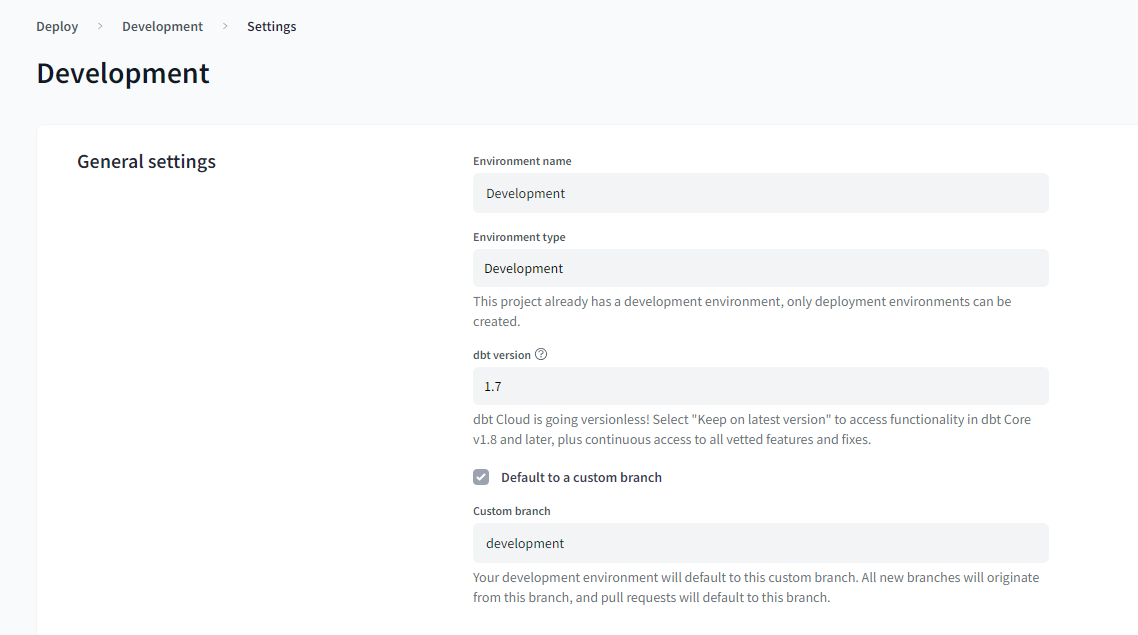
I assume you are also able to assign a default branche to each environment, same way how dbt cloud works:
1 Like
So the most simple process with two environments would be:
- Create branche X from development
- Do the changes in branche X
- Merge the changes to development
- After any automatic checks (CI/CD), merge to master/production branche.
1 Like
Hi @Abdel ,
Yes, it is possible to have custom environment variables. We’re working on that.
Could you share more about the use case/what kind of variables you want to use?
Best,